1 - 多线程编程概述
几十年前,程序都是单线程的,CPU市场竞争的是最高频率。但在05年左右单核处理器的性能达到瓶颈,CPU市场开始竞争单个处理器芯片中的最多核心数目,多线程编程便开始发展,并成为主流。通过多线程编程课并行执行多个计算,充分利用系统中多个处理器单元。
C++98/03不支持多线程编程,必须借助第三方库或目标操作系统的多线程API,十分麻烦;而从C++11开始,有了一个标准的多线程库,使编写跨平台的多线程应用程序更容易了。
本文将会介绍一些多线程编程相关的概念,例如并行和并发的区别,什么是争用条件等。
并行与并发
首先要了解的就是并行和并发的区别。一句话来说,并行是 同时在不同的处理器上处理不同的任务,并发是 “同时”在一个处理器上处理多个任务。
并行(Parallelism)
并行是指有多个处理器,每个处理器各执行一个线程,互不抢占CPU资源,如果线程数量多于CPU,也没办法,只能将处理器时间划分为多个时间段,然后将时间段分配给各个线程。

并发(Concurrency)
并发是指只有一个处理器,但多个线程被轮换快速执行,使得宏观上有了同时执行的效果。作用原理是将单处理器时间划分为多个时间段,再分配给不同线程。同一时间段只能有一个线程在运行,其余线程均处于挂起状态。

多线程的重要性
- 编写多线程程序,可以把计算问题分解为可互相独立运行的小块,从而获得巨大性能提升。
- 可以在正交轴上对计算任务模块化,例如用户UI和计算分为两个线程,这样后台在进行长时间计算时,用户界面仍然可以响应。
下图是一个并行计算的例子:
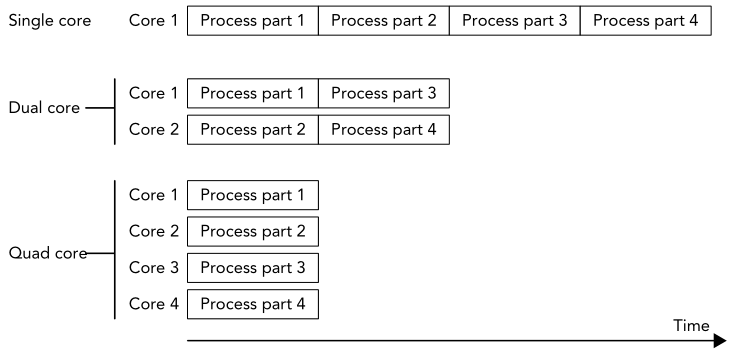
可以发现采用并行计算大大减少了程序的运行时间。
多线程编程的一个难点就是将算法并行化,这个过程和算法的类型高度相关。其他难点是防止争用条件,死锁,撕裂和伪共享等问题,可以通过原子操作或显式同步机制解决。
接下来将介绍多线程编程的难点。
多线程的难点
争用条件(Race Condition)
当多个线程要访问任何种类的共享资源时,可能发生争用条件。其中,有种叫做“数据争用”的争用条件,当多线程访问共享内存,且至少有一个线程写入共享内存时,就会发生数据争用。
例如下表,有一个自增线程和一个自减线程,对共享内存中的一个值进行相关操作:
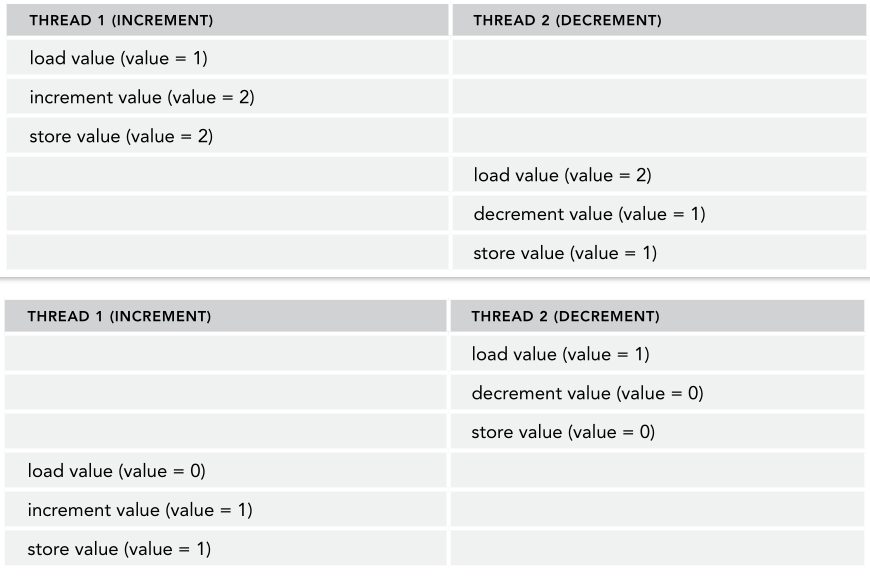
理想情况下是这样,但多线程条件下,指令会交错执行,有一种可能如下:
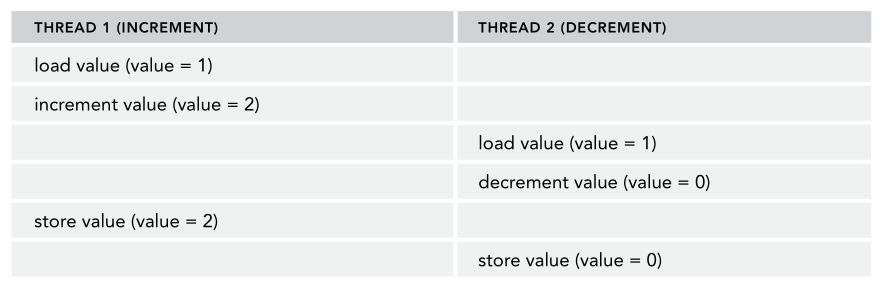
结果是0而不是1,发生了争用条件。
撕裂(Tearing)
撕裂是数据争用的特例或结果,分为 撕裂读(torn read) 和 撕裂写(torn write) 两种类型:
- 撕裂读:线程将数据的一部分写入内存,还有部分数据未写入,此时其他线程会读到不一致的数据。
- 撕裂写:两个线程同时写入数据,导致最终结果不一致。
死锁(Deadlocks)
可能会用互斥等同步方法来解决争用条件的问题,但这样做还有可能会碰到死锁问题。死锁指的是多个线程因为互相等待访问另一个线程锁定的资源而造成无限阻塞现象。
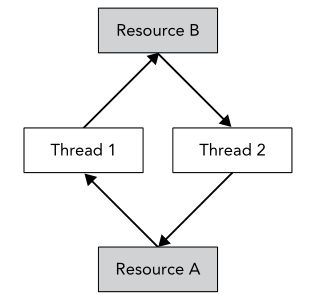
例如有两个线程和两个被互斥对象A, B保护的资源,这两个线程尝试以下表方式运行:

假设某次运行顺序是这样的:
- 线程1:获取A
- 线程2:获取B
- 线程1:获取B,此时由于线程2占用B,线程1等待
- 线程2:获取A,此时由于线程1占用A,线程2等待
这样两个线程都在等待对方释放资源,发生死锁。死锁情况下的资源获取情况通常是一个环:
为了避免死锁发生,有的人会让线程以相同顺序获取资源,也会在死锁发生时采用等待并睡眠等方式去解决问题。
但这些方法始终避免不了死锁问题,如果需要获得由多个互斥对象保护的多个资源的权限,而非单独获取每个资源的权限,推荐使用后面提到的std::lock()或std::try_lock()函数。这两个函数仅需通过一次调用,即可获取/尝试获取多个资源的权限,而且避免死锁问题。
伪共享(False-Sharing)
大多数缓存都使用所谓的“缓存行(Cache Line)”,通常是64字节。如图,如果代码结构设计不当,就会导致多个线程使用同一个缓存行的数据,如果其中一个线程要进行写入操作,就会锁定该缓存行,导致其他线程被阻塞,大大影响性能。
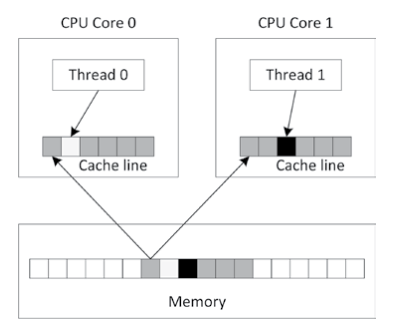
可以使用显式内存对齐方式优化数据结构,确保多个线程处理的数据不共享任何缓存行。一种简便的方法是用C++17引入的hardware_destructive_interference_size常量和alignas关键字来合理地对齐数据。
hardware_destructive_interference_size:在<new>中定义,为避免共享缓存行,返回两个并发访问的对象之间的建议偏移量。
参考资料
- 飘零的落花 - 现代C++详解
- C++20高级编程