107-【八股】引擎&图形学
图形学
渲染管线
渲染管线的构成
在概念上可以将图形渲染管线分为四个阶段:
应用程序阶段:在CPU端完成,该阶段主要是在软件层面上执行的一些工作,包括空间加速算法、视锥剔除、碰撞检测、动画物理模拟等。
大体逻辑是,执行视锥剔除,查询出可能需要绘制的图元并生成渲染数据,设置渲染状态和绑定各种Shader参数,调用DrawCall,交给GPU渲染。
几何处理阶段:负责大部分多边形操作和顶点操作,将三维空间的数据转换为二维空间的数据。
顶点处理阶段:执行顶点变换和着色的工作,通过MVP矩阵将顶点从局部空间转换到屏幕裁剪空间,方便后续转为NDC坐标。
还可以进行顶点着色计算,如Flat shading和Gouraud Shading。
之后有一些可选阶段,例如曲面细分等。
裁剪阶段:裁剪掉不在屏幕内部的图元,由硬件控制。
在CPU已经视锥体剔除了,为什么这里还要裁剪?
主要是两次裁剪的粒度不同。CPU端的视锥体剔除是根据物体包围盒是否在视锥体内,针对整个物体裁剪;而这里的裁剪则是针对图元单位裁剪。
屏幕映射阶段:将之前步骤得到的坐标映射为标准屏幕坐标NDC。
光栅化阶段:将图元离散化成片段的过程.
- 三角形设置:计算出三角形的一些重要数据(如三条边的方程、深度值等)以供三角形遍历阶段使用,这些数据同样可用于各种着色数据的插值。
- 三角形遍历:找到哪些像素被三角形所覆盖,并对这些像素的属性值进行插值。通过判断像素的中心采样点是否被三角形覆盖来决定该像素是否要生成片段。通过三角形三个顶点的属性数据,插值得到每个像素的属性值。此外透视校正插值也在这个阶段执行。
像素处理阶段:给每一个像素正确配色,最后绘制出整幅图。
- 像素着色:进行光照计算和阴影处理,决定屏幕像素的最终颜色。各种复杂的着色模型、光照计算都是在这个阶段完成。
- 测试合并:包括各种测试和混合操作,如裁剪测试、透明测试、模板测试、深度测试以及颜色混合等。经过了测试合并阶段,并存到帧缓冲的像素值,才是最终呈现在屏幕上的图像。
各种测试及其顺序
裁剪测试:在裁剪测试中,允许程序员开设一个裁剪框,只有在裁剪框内的片元才会被显示出来,在裁剪框外的片元皆被剔除。裁切测试可以避免当视口比屏幕窗口小时造成的渲染浪费问题。
透明测试(Alpha测试):根据物体的透明度来决定是否渲染。
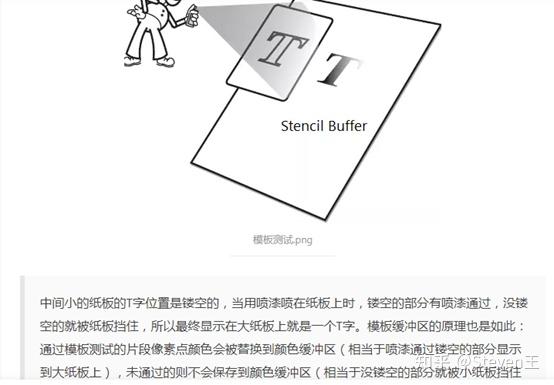
模板测试:根据物体的位置范围决定是否渲染。
![]()
深度测试:根据物体的深度决定是否渲染。
前向渲染管线和延迟渲染管线
前向渲染是一种传统方式,每绘制一个物体就计算光照并输出像素颜色,优点是流程简单,容易支持透明和抗锯齿; 延迟渲染则把几何信息和光照解耦,先写入 G-buffer,再统一光照,适合大量光源的场景,但处理透明和 MSAA 比较复杂。 两者各有优缺点,现代引擎(比如 Unreal)也常用混合管线,根据对象类型选择前向或延迟。
在前向渲染管线下,如何处理大量点光源问题?
前向渲染本身在处理大量点光源时容易遇到性能瓶颈,因为每个像素可能需要对多个光源做光照计算。为了解决这个问题,有几种优化策略可以使用:
Light Culling(光源剔除)
在渲染之前,为每个物体或每个屏幕分区(比如 tile)确定哪些光源真正影响它。只对这些光源做光照计算,避免冗余遍历。
- 可以基于距离、包围盒、遮挡信息做裁剪
- 常见做法:基于视锥体剔除 + 包围球光照范围
Forward+(或 Tiled Forward Shading)
这是传统前向渲染的一个现代变种,结合了延迟渲染的 tile-based 思想:
- 将屏幕分成 tile(比如 16x16 像素块);
- 用计算着色器构建每个 tile 内影响它的光源列表;
- 渲染时只考虑当前 tile 的光源,显著减少计算量。
优点:
- 保留前向渲染对透明/抗锯齿的支持
- 同时支持大量动态光源
使用 Clustered Forward Rendering(高级优化)
类似 Forward+,但将屏幕按空间划分成 3D 网格(cluster),再为每个 cluster 绑定影响光源,适合处理光源数量更极端的场景。
光源分层 + 预计算技术
- 静态光源 → 使用 Lightmap 或 Spherical Harmonics 预烘焙
- 仅对动态光源使用实时光照计算
这可以大幅减轻每帧的光照压力。
GPU-Driven
在调用GPU绘制指令之前,渲染所需的资源需要经过一定程度的处理,包括合批、剔除、搜集DrawCall等。传统引擎中,这个流程是在CPU端完成的,称之为“CPU Driven”。
随着场景复杂度的要求以及CPU并发上限的限制,CPU Driven迎来了性能瓶颈。另一方面,GPU硬件的提升以及GPU天然的高并发特性,原本在CPU上处理的复杂工作可以搬迁到GPU上处理,也就是GPU Driven。
PBR
概念
基于物理的渲染,是指在渲染过程中,有关材质、光照、相机、光传输等都要基于准确的物理定律。
实现
使用Cook-Torrance模型实现PBR,这个BRDF模型有漫反射和镜面反射两部分组成:
然后是镜面反射项:
- 法线分布函数:Normal Distribution Function,估算在受到表面粗糙度的影响下,朝向方向与半程向量一致的微表面的数量。
- 菲涅尔函数:Fresnel Equation,描述的是在不同的表面角下表面所反射的光线所占的比率。
- 几何函数:Geometry Function,描述了微表面自成阴影的属性。当一个平面相对比较粗糙的时候,平面表面上的微表面有可能挡住其他的微表面从而减少表面所反射的光线。
这三个函数有很多实现。UE4 中所使用的是:
- D 项使用 Trowbridge-Reitz GGX,
- F 项使用 Fresnel-Schlick 近似,
- G 项使用 Smith’s Schlick-GGX。
阴影技术
Shadow Mapping
原理
- 从每个光源的位置渲染一遍场景,将得到的深度信息写入到贴图中,
- 正常渲染一次场景,利用得到的shadowmap来判断哪些片段落在了阴影中。
常见问题
光源VP矩阵的选择:平行光选用正交投影,点光源和聚光灯选用透视投影。需要注意的是,在透视投影得到的深度贴图中,深度值是 非线性的,在正式使用之前需要进行线性化操作。
// 线性化操作 float LinearizeDepth(float depth) { float z = depth * 2.0 - 1.0; // Back to NDC return (2.0 * near_plane * far_plane) / (far_plane + near_plane - z * (far_plane - near_plane)); }阴影抖动问题:可以通过偏移技术来解决,增加一个bias来比较片段深度,还有更好的一种方式是使用一种自适应偏移的方案,基于斜率去计算当前深度要加的偏移;
阴影锯齿问题:可以使用百分比渐进过滤(PCF)技术进行解决:从深度贴图中多次采样,每次采样坐标都稍有些不同,比如上下左右各取9个点进行采样(即一个九宫格),最后加权平均处理,就可以得到柔和的阴影。标准PCF算法采样点的位置比较规则,最后呈现的阴影还是会看出一块一块的Pattern(图块),可以采用一些随机的样本位置,比如Poisson Disk来改善PCF的效果.
采样Shadowmap的时候,需要将标准设备坐标系的坐标范围由[-1,1]修正到[0,1],否则贴图的坐标范围是[0,1],会采样错误。
CSM
如果分层的Shadow Map过多,如何优化避免每帧都全部绘制以上贴图?
可以采用 逐层更新(cascade update scheduling)、静态对象缓存(shadow map reuse)、视野/相机运动感知更新等方式,避免每帧全部更新 8 层,提高性能:
按需更新 Cascade(Update Scheduling)
- 不同层级的 Shadow Map 作用于不同距离:
- 近层(C0~C2):更新频率高,每帧都更新;
- 中远层(C3~C7):距离远,可每几帧更新一次;
- 不同层级的 Shadow Map 作用于不同距离:
运动检测(Camera Movement-aware Update)
- 只有相机移动超过一定阈值时才更新对应层;
- 中远层因为几何投影变化缓慢,可延迟更新;
- 甚至可以用视锥包围盒与上次投影比较判断是否重建 Shadow Map。
✅ 原理参考:Temporal CSM / Lazy Update CSM
静态对象 Shadow Cache(Shadow Map Reuse)
- 将场景中静态物体的 Shadow 渲染结果缓存;
- 每帧合并动态物体的阴影渲染结果;
- 静态层用多层贴图叠加方式复用之前的结果,节省大量 draw call;
✅ 技术:Shadow Atlas + Static Shadow Cache
层级分辨率动态控制
- 越远的 Cascade 阴影图分辨率降低(例如 2048 → 1024 → 512);
- 节省内存带宽和渲染时间;
- 有些引擎支持按 Cascade 距离动态调整分辨率。
GPU Compute Raster / Ray Query Shadows(可选方向)
- 使用 Compute Shader 或 DXR/HW RayTracing 加速中远层级阴影生成;
- 也可用于软阴影模糊阶段优化。
CSM 的核心优化策略是“按需更新 + 静态缓存”,我们并不需要每帧更新所有 Cascade,而是基于 层级权重、相机移动、物体是否静态 做智能判断,实现性能与质量的最佳平衡。
PCSS
Mipmap
概念
Mipmap(多级渐远纹理) 是一种优化纹理采样性能和质量的技术,它为一张原始纹理生成多个尺寸逐级减半的版本(通常是
原理
Mipmap 是一组纹理链:
- Level 0:原始大小
- Level 1:宽高减半
- Level 2:继续减半,直到 1×1
GPU 根据片元与相机的距离(或者像素覆盖率),自动选择合适的 Mipmap Level 采样;
结合 三线性过滤(Trilinear Filtering) 可实现 Level 之间的平滑过渡。
优点
| 优势类型 | 说明 |
|---|---|
| ✅ 提升性能 | 远处使用小纹理,减少内存带宽消耗 |
| ✅ 消除闪烁 | 降低 Moiré、锯齿、采样混叠 |
| ✅ 提升缓存命中率 | 更小贴图更可能被 GPU 纹理缓存命中 |
应用
- 纹理采样优化(默认用途)
- 所有表面贴图几乎都启用 Mipmap;
- 自动适应不同视角、缩放距离。
- 阴影贴图优化(Shadow Map Mipmap)
- 用于软阴影模糊(PCF、VSM、ESM 等);
- 提供多层模糊强度。
- LOD 选择辅助(物体/贴图切换)
- Mipmap Level 可作为对象或材质 LOD 的参考依据;
- 用于高阶渲染算法如 POM(Parallax Occlusion Mapping)。
- GPU 粒子模拟、环境遮蔽(AO)等
- Mipmap 被用于高斯模糊、深度模糊时的分级;
- G-Buffer 的 Blur Pass 或 AO Pass 常使用。
问题
512x512的贴图,开启Mipmap后大小多少
开启 Mipmap 后,会额外生成
对一张
抗锯齿
光栅化的时候,是以像素中心点是否被三角形覆盖来决定是否生成片段,因此有些片段覆盖了采样点就生成,有些没有覆盖就不生成,最终导致了锯齿现象。
SSAA
向原画面大 x 倍的画面进行降采样,性能要求高。
MSAA
只对必要的地方(如边缘处)进行单画面 x 倍采样,也有一定性能要求,尤其是场景三角形数量极大时。
FXAA
即 Fast Approximate AA,快速近似 AA。它将每帧画面的边界提取出来,然后对其进行插值处理以达到快速近似 AA 的目的。
步骤:
- 寻找整体画面边界:将画面的颜色空间从 RGB 转换到 HSL/HSV,根据亮度寻找;
- 计算 AA 的混合朝向:对边界进行水平和垂直方向的滤波计算,比较二者的值得出朝向,方便进行后序混合操作;
- 搜寻与朝向点相邻的部分边界:使用边界搜寻算法找到和朝向点相邻的部分边界;
- 计算混合程度:知道朝向和部分边界后,就能求边界点沿朝向采样的程度了。利用类似相似三角形的原理,通过边界信息求自身的偏移值。
TAA
利用时序上的数据(上一帧信息 + Motion Vector)进行 AA 操作。
后处理技术
模糊
高斯模糊
优化
在处理千万级别顶点数量的大型3D场景时,如何提升渲染效率和优化用户交互体验
在千万级顶点的 3D 场景中,可以通过 渲染优化 和 交互优化 结合使用,以提高效率:
渲染优化
- 批处理(Instancing、Mesh Merging)
- 视锥裁剪(Frustum Culling)
- LOD 细节控制
- 纹理优化(Mipmap、压缩)
- 计算着色器加速
交互优化
- 多线程渲染
- 异步加载
- 遮挡剔除(Occlusion Culling)
物体多、贴图多,Mipmap 也多时,如何优化加载与渲染性能?
贴图资源多时,可通过 贴图合并(Texture Atlas)、按需加载(Streaming Mipmap)、贴图 LOD 管理 和 压缩纹理格式 等手段减少内存占用、带宽压力和加载时长,提高渲染效率。
- Texture Streaming(按需加载)
✅ 核心思想:只加载当前视野所需的贴图层级(尤其是近景高分 Mipmap),远处或遮挡的使用低分 LOD 或空白贴图。
- 引擎根据相机位置 + 每帧资源预算进行动态加载;
- LOD 越低,贴图越小,加载越快;
- Unreal、Unity 都自带 Texture Streaming 系统。
📌 优化点:
- 限制 Streaming Pool 大小,防止爆显存;
- 避免每帧过多 Streaming 造成卡顿(异步加载 + Streaming Scheduler)
- 虚拟纹理(Virtual Texturing / VT)
✅ 核心思想:类似分页内存系统,纹理切成 Tile(页),运行时只加载屏幕上可见部分。
- 每张贴图有页表(Page Table),GPU 动态从磁盘/内存加载必要 Mipmap Tile;
- UE5 的 Virtual Texture 和 SVT(Sparse Virtual Texture) 是典型实现;
- 可同时管理海量贴图(超高分地形、角色等)且不卡顿。
📌 优点:
- GPU 显存占用极低;
- 支持非常大的贴图集,如 8K、16K 分辨率资源。
- 压缩纹理格式(如 BCn / ASTC / ETC2)
✅ 使用 GPU 原生支持的压缩纹理格式,可以极大减小贴图和 Mipmap 的显存占用,提升加载速度。
| 格式 | 平均压缩比 | 支持平台 |
|---|---|---|
| DXT / BC1~BC7 | 6:1 ~ 4:1 | PC, Console |
| ASTC | 灵活 | 移动端, Vulkan |
| ETC2 | OpenGL ES | Android, WebGL2 |
📌 优化点:
- 所有 Mipmap 一并压缩,解压由 GPU 自动完成;
- 配合 Streaming 效果最佳。
- Texture Atlas(合图)
✅ 将多张小贴图合并成一张大贴图,减少 draw call 和贴图绑定开销。
- Sprite、UI、小物件常用;
- 需注意 UV 重映射;
- 会限制部分 Mipmap 使用(局部失效)
- 物体 LOD + 贴图 LOD 联动
✅ 对远距离模型使用更低分辨率的 mesh + 更低级别贴图(LOD 与 Mipmap 联动);
- UE / Unity 支持基于距离自动切换 mesh + material;
- 避免加载和渲染高分贴图。
- 加载顺序优化 + 预热
- 首帧/场景切换提前加载所需贴图 Mipmap;
- 常见的贴图优先排在 Asset Bundle 前列;
- 异步加载与 GPU 预热配合,避免卡顿。
面对贴图和 Mipmap 多的复杂场景,我们可以从“加载策略、压缩格式、内存调度和 LOD 体系”四个维度全面优化,既保证渲染质量,也确保性能稳定。
数学
向量
点乘, 叉乘的公式和几何意义
点乘:
- 求一个向量到另一个向量的投影;
- 判断两向量是否同方向;
- 找到两向量夹角;
- 计算向量大小;
- 沿某向量进行正交分解;
叉乘:
- 判断点在三角形的内/外侧
- 判断点在直线的左/右侧
向量叉乘的方向是通过右手定则(Right-hand rule)来确定的。
矩阵
3D的SRT变换
缩放:
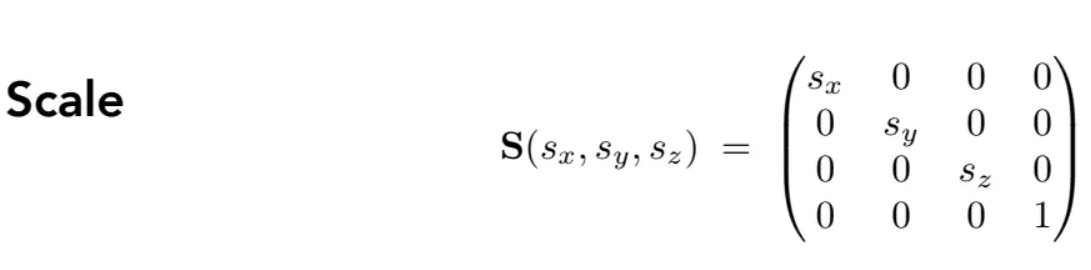
绕x轴旋转:
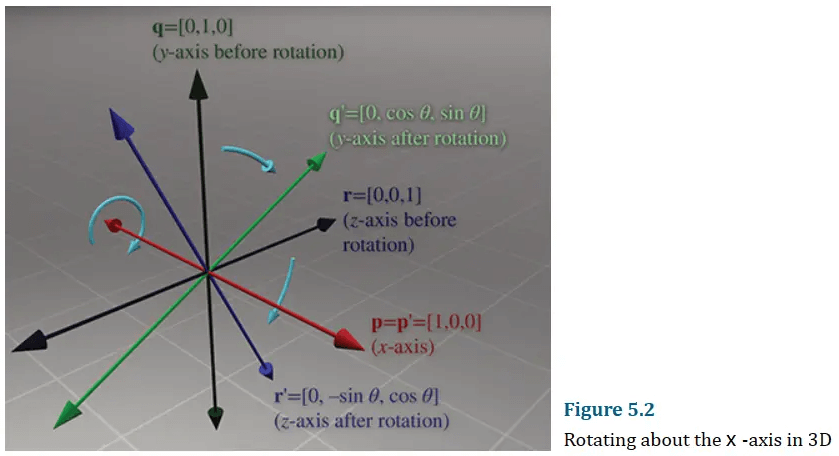
前面的文章说过,矩阵其实是向量的数组,因此我们可以用三个轴的方向向量来表示一个旋转矩阵。按照上图描述,基本旋转矩阵为:
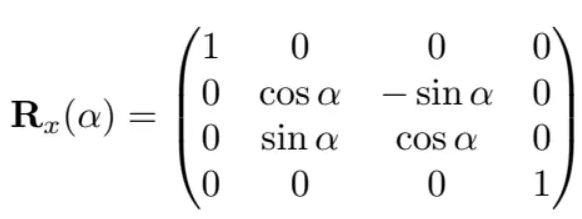
类似的,绕y轴旋转为:
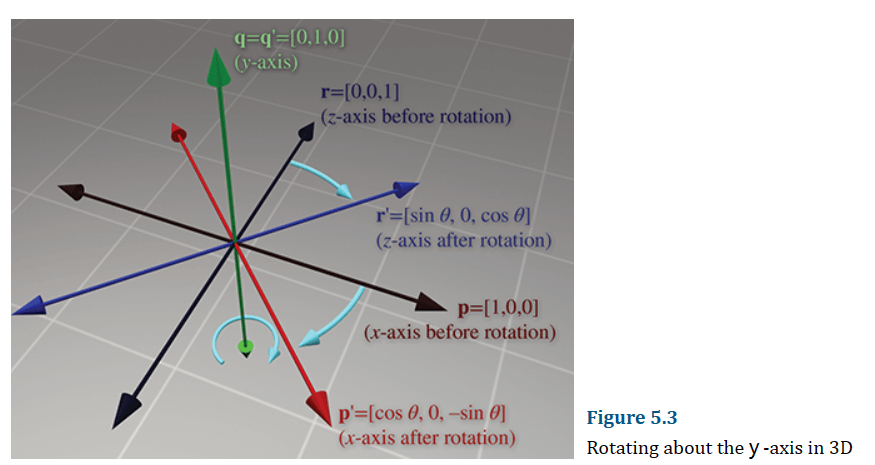
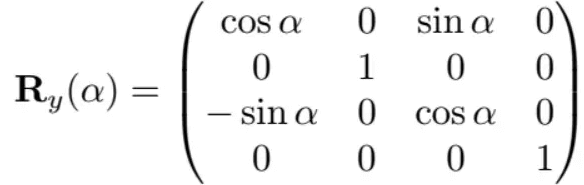
绕z轴旋转为:
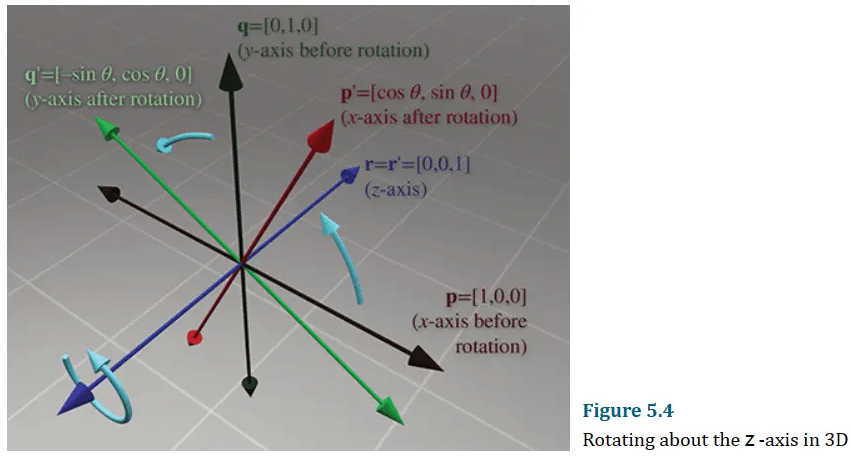
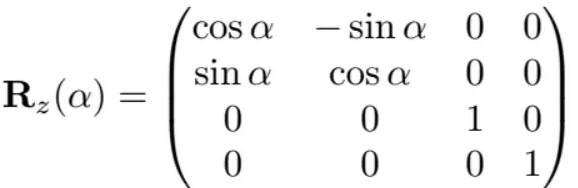
平移:
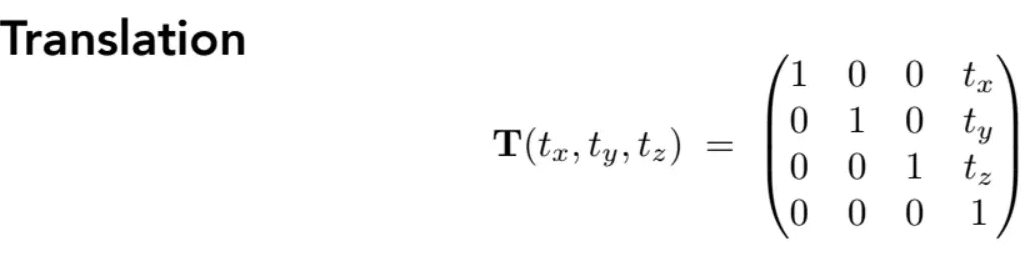
通过SRT变换,也就是MVP变换中的M,将模型的点由局部坐标转换为世界坐标。
常见问题:
- 是否可逆:SRT变换属于线性变换,线性变换与平移变换合起来为仿射变换,它们都是可逆的(除了投影变换外都可逆)。
- SRT和TRS的结果是否相同:结果并不一样,这是因为像旋转和缩放这样的转换是相对于坐标系原点进行的。 缩放以原点为中心的对象产生的结果不同于缩放远离原点的对象所产生的结果。 同样,旋转以原点为中心的对象产生的结果不同于旋转远离原点的对象所产生的结果。
物理引擎
像彩虹六号中的墙体破碎那种“非实时”物理,是怎么实现的?
这类墙体破坏通常采用预计算(预烘焙)破坏模型 + 状态触发系统,而不是实时物理模拟。游戏中根据玩家行为触发“已准备好的破坏效果”,既节省性能又保持视觉真实。
| 类型 | 技术 |
|---|---|
| 可破坏墙体 | 预定义破坏块 + 逻辑剖面系统 |
| 穿孔弹道 | 弹道系统确定命中点 + 改变 mesh 或贴图 |
| 大块破坏 | 使用“事先建模的”碎块 + 动画或物理动态开启 |
| 网格更新 | 使用 Geometry Collection 或 Dynamic Mesh 替换 |
这类非实时破坏系统的关键在于“预定义资源 + 精准触发逻辑”的组合,通过欺骗视觉和节省计算,实现游戏中的“高质量破坏体验”,是 AAA 战术射击类游戏物理设计中的常规手段。
如果墙体破碎后产生10万个碎片,如何优化
如果同时启用10万个刚体和渲染实体,性能会崩溃。实际中会通过 碎片分批激活、距离剔除、粒子混合、LOD 替换 等多种策略控制性能负载:
- 延迟激活 / 动态启用碎片物理
- 默认碎片处于静态不可动状态(sleep/disabled);
- 玩家靠近或炸到时才启用一小部分碎片的刚体模拟;
- 没有参与交互的碎片不会占用 CPU/GPU。
- 远距离碎片合并 / 粒子替代
- 离玩家很远或不在视线内的碎片,用粒子系统或低面数代理 mesh替代;
- 也可将多个碎片合并为一个远 LOD 模型,节省 draw call;
- GPU Instance 渲染 / Cluster Culling
- 渲染层用 GPU Instancing 或 Nanite 类似机制批量绘制碎片;
- 不可见/小碎片按 cluster 剔除或合批处理;
- 生命周期控制
- 每个碎片有生命期:比如炸飞 5 秒后自动移除或回收;
- 长时间不动碎片转为静态 mesh,不参与物理计算。
- LOD 切换+贴图替代
- 某些破坏只用贴图变化(decals),不是真的 mesh 替换;
- 或者大碎块逐步替换成静态贴图/模型。
面对大规模碎片,我们的目标不是“每个都物理模拟”,而是“让玩家看起来像是全部真实破碎”,通过分批启用、实例渲染、距离控制等手段做到了视觉冲击力与性能之间的最佳平衡。
游戏引擎
UE5新特性
Nanite:虚拟微多边形几何体技术
Nanite 是 UE5 引入的一项虚拟化几何体系统,允许引擎实时渲染数十亿个多边形的高精度模型,无需手动创建 LOD(细节层次)或担心绘制调用数量。这使得开发者可以直接使用高精度模型,极大地提高了渲染效率和视觉质量。
原理
分为离线预处理和运行时渲染两部分:
预处理:
Cluster切分:将模型拆分为若干Cluster面片块,并给这些Cluster分组。
对于一个模型,将其Mesh中每相互临近的128个Triangle组合在一个结构下,组合后的结构便称之为Cluster。如下图中一个个色块即为一个Cluster,每个Cluster内包含了128个Triangle。这个Cluster的分割过程通过Metis库完成(设定为128个Triangle的原因是为了迎合Memory Cache)
此外,数个Cluster(8-32个)又组成了另一种结构,称之为Cluster Group。
生成LOD:在分组Cluster作为LOD0的基础上,自动生成其他等级的分组Cluster。
模型被Cluster Group切分后,便能更为细致地去控制局部的LOD。这意味着切换LOD不再是切换整个模型,而是单个模型的局部,也就是Cluster Group切换LOD。
怎么生成这些LOD的数据?
首先以Cluster Group为单位,对Cluster Group结构内的Mesh进行简化(这个Mesh就是Group内的所有Cluster的Triangle总和,简化算法为Quadric Error Matrics)。在得到了低精度的Mesh之后,重新将这些Triangle进行组合,变成多个Cluster。最后再将多个Cluster重新组合为Cluster Group。
这便是下一级LOD的数据。等于在获得低精度的Mesh之后,重新运行了第一步的Cluster切分。
为什么不用通过简化Cluster的方式来生成LOD?
如果通过此方式生成LOD,会导致在不同LOD等级间Mesh边缘出现裂缝T-Junction现象,为了解决此现象需要退化网格,在简化Mesh时锁住每个Cluster的边缘。但这样的后果就是在简化后,边缘区域依旧是非常复杂的Mesh,而非边缘区却很简单。这会在LOD切换时带来视觉上的异样,况且由于Cluster的数量众多,异样感会特别显著。
构建BVH:为了运行时的剔除工作做准备,需要用BVH的结构来组织Cluster Group。
数据压缩:用高效压缩算法压缩特殊编码的数据。
运行时:
- GPU Driven 剔除:首先对整个Mesh进行视锥剔除和遮挡剔除,这一步被称作 instancing culling;然后用离线构建好的BVH对Cluster Group进行剔除,这一步被称作 hierarchical/persistent culling;最后对Cluster进行视锥剔除和遮挡剔除,这一步被称作 Cluster Culling。
- 光栅化:对于大面片,使用GPU硬件光栅化;对于小面片,使用Compute shader进行软光栅化(三角形扫描线算法);
- 输出G-Buffer:将生成的结果Visiblity Buffer转换为G-Buffer。
Lumen:全动态全局光照系统
Lumen 是 UE5 的全局光照解决方案,支持实时的全局光照和反射,无需预先烘焙光照贴图。这使得场景中的光照变化更加自然和动态,提升了视觉真实感。
World Partition:世界分区系统
World Partition 系统重新设计了世界管理方式,将整个世界划分为网格,并根据玩家的位置动态加载和卸载区域。这简化了大规模开放世界的构建和管理,提高了开发效率。
MetaSounds:高级音频系统
MetaSounds 是 UE5 引入的全新音频系统,提供了类似材质编辑器的图形化界面,允许开发者以更精细的方式控制音频行为,实现更复杂的音频效果和响应。
Niagara:模块化粒子特效系统
Niagara 是 UE5 的主要视觉特效系统,取代了 UE4 中的 Cascade。它提供了更强大的粒子控制能力,允许开发者创建复杂的粒子效果,如烟雾、火焰、魔法等。Niagara 使用模块化设计,开发者可以通过图形化界面或脚本编写自定义粒子行为。
Niagara 还支持 GPU 加速和实时预览,使得特效的开发和调试更加高效。
Chaos:全新物理与破坏系统
Chaos 是 UE5 默认的物理引擎,取代了 UE4 中的 PhysX。它提供了更高效的刚体模拟、布料模拟、车辆物理和破坏系统。Chaos 支持实时布娃娃物理(Ragdoll Physics),允许角色在受到力作用时表现出自然的物理反应。
此外,Chaos 还支持大规模场景的物理模拟和网络同步,适用于需要高保真物理效果的游戏和应用。
MegaLights:高性能多光源照明系统
MegaLights 是 UE5.5 中引入的一项新功能,旨在优化动态区域光源的渲染性能。它允许艺术家在场景中放置大量动态且带阴影的区域光源,同时保持较低的性能开销。MegaLights 支持光线追踪阴影,使得使用纹理区域光源等高质量光源成为可能。该技术类似于 NVIDIA 的 RTXDI(RTX Dynamic Illumination)。
MegaLights作为ReGir的变种,通过恒定的GPU开销来支持 [数量无关] 的超大规模灯光的同屏渲染——它每帧每个像素采样的灯光数和发出的光线数均恒定,所以即使灯光数量增加,MegaLights的单帧耗时不增。
参考资料
- 【游戏开发面经汇总】- 图形学基础篇 - 知乎 (zhihu.com)
- Nanite解读笔记 - 知乎
- GPU Driven Render Pipeline - 知乎
- ChatGPT,DeepSeek等AI