01 - 引擎工具链基础
本文将简要介绍一些游戏引擎工具链的相关的基础概念,内容包括:
- 什么是引擎工具链
- 复杂的工具GUI
- 游戏资产的管理
- 增强工具链的健壮性
- 如何制作工具链
- 引擎的插件
碎碎念:加油啊我,不知道能不能找到工作……
什么是引擎工具链
我们目前所接触到的都是引擎的核心组件,这些组件构成了运行时引擎。而用户真正操作的不是引擎核心,而是在此之上的各种编辑器/工具链,如下图。对于商业级的引擎来说,这些编辑器/工具链的代码复杂度会比运行时引擎高。
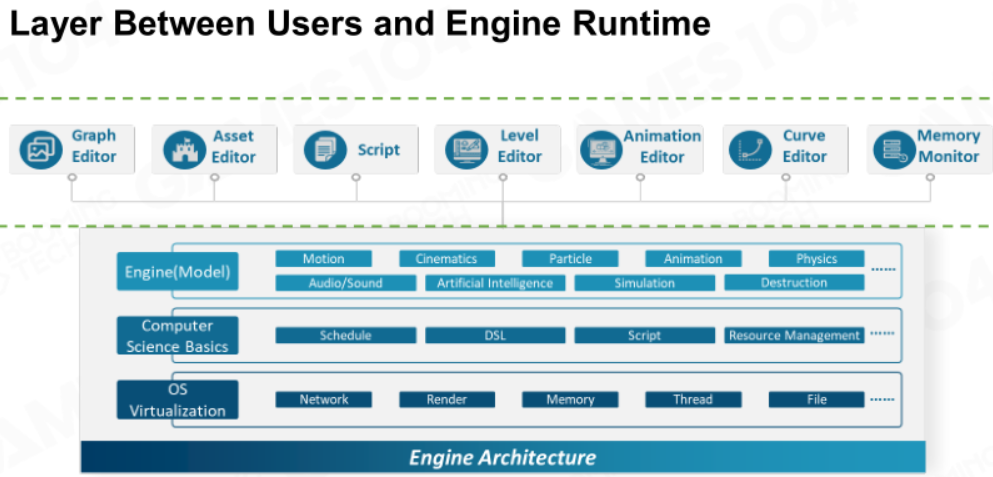
DCC工具与游戏引擎
PS,Blender等DCC(Digital Content Creation,数字内容生成)工具为游戏制作各种格式不同的资源,需要通过引擎的Asset Conditioning Pipeline变为引擎内部的统一素材格式,这个管线就是工具链的一部分。
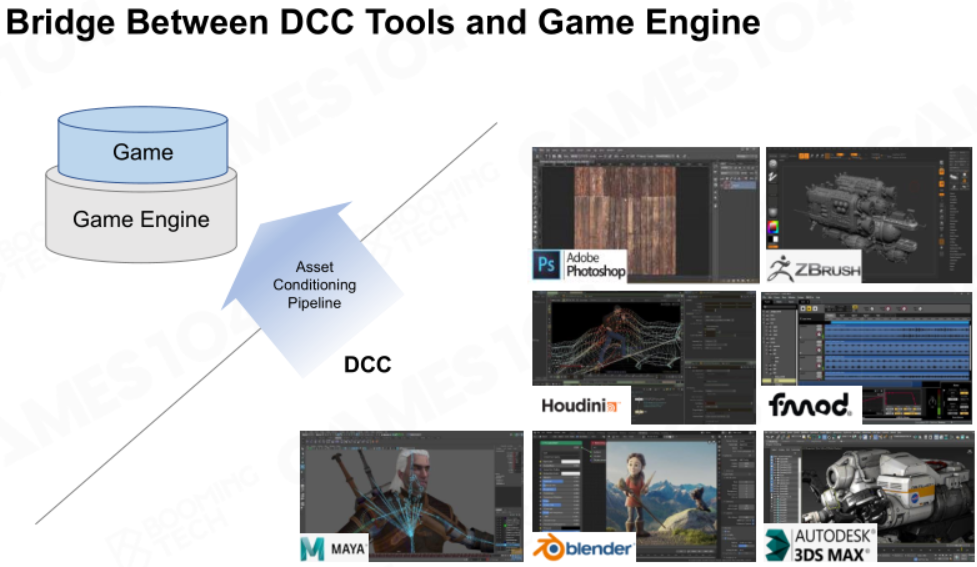
不同类型的人协同工作
引擎工具链的作用还在于让不同类型的人协同工作,例如让策划快速搭建关卡原型(World Outliner等),让美术做出高质量效果(材质编辑器、粒子编辑器等),让程序做出正确的逻辑(Debug view等)。
复杂的工具GUI
图形用户界面GUI
要做工具链首先得明白GUI,现在GUI的实现也越来越复杂了。

GUI绘制模式
即时模式
即时模式 API 是过程性的。 每次绘制新帧时,应用程序都会直接发出绘图命令。 图形库不会在帧之间存储场景模型。 相反,应用程序会跟踪场景。
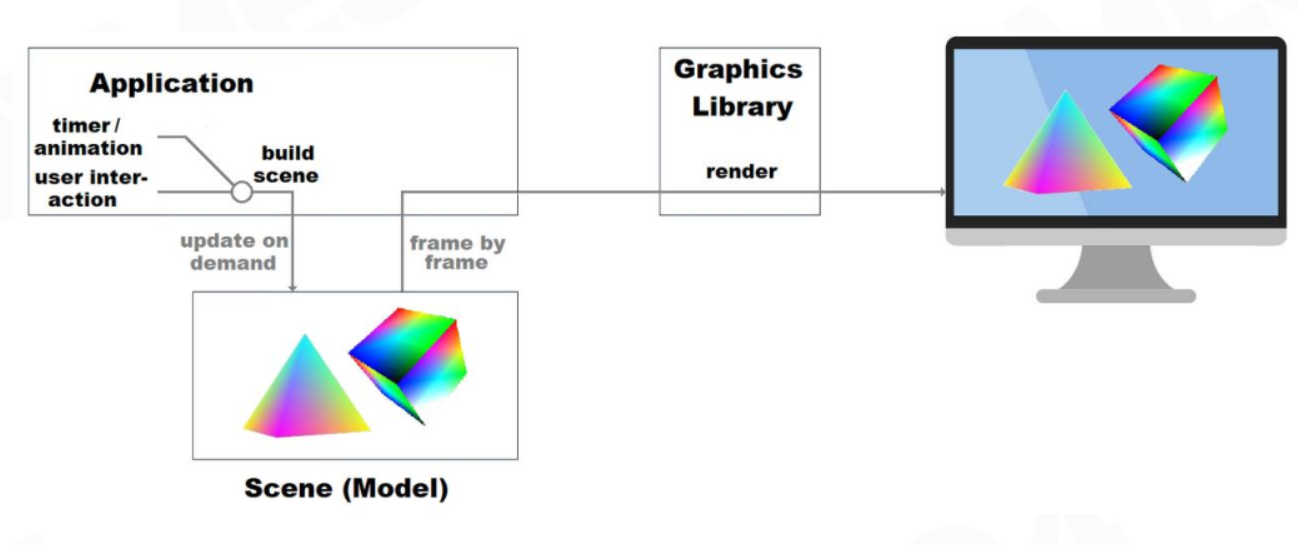
它的特点,优缺点如下:

保留模式
保留模式 API 是声明性的。 应用程序从图形基元(如形状和线条)构造场景。 图形库将场景的模型存储在内存中。 为了绘制帧,图形库将场景转换为一组绘图命令。 在帧之间,图形库将场景保留在内存中。 若要更改呈现的内容,应用程序会发出命令来更新场景,例如添加或删除形状。 然后,该库负责重绘场景。
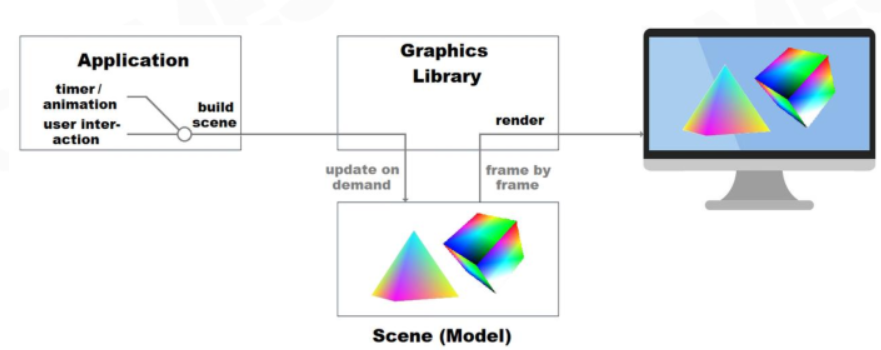
它的特点,优缺点如下:

GUI设计模式
在写一套工具时,建议都遵循某个设计模式,否则后面会越写越乱。对于GUI工具链来说,常用到的设计模式有如下几种:
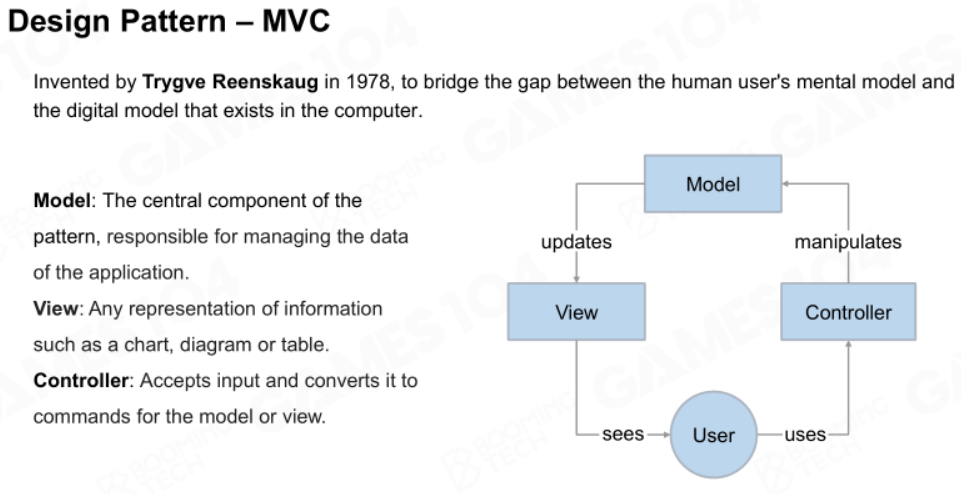
MVC
MVC设计模式可以有效解耦合UI层和逻辑层,整体分为三部分:
- Model:设计模式的中心组件,负责管理应用的数据;
- View:任何数据的表现形式,例如图表;
- Controller:接收一些输入来改变Model中的数据,或者View的呈现方式。
用户通过Controller来控制Model的更新,Model控制View的更新。
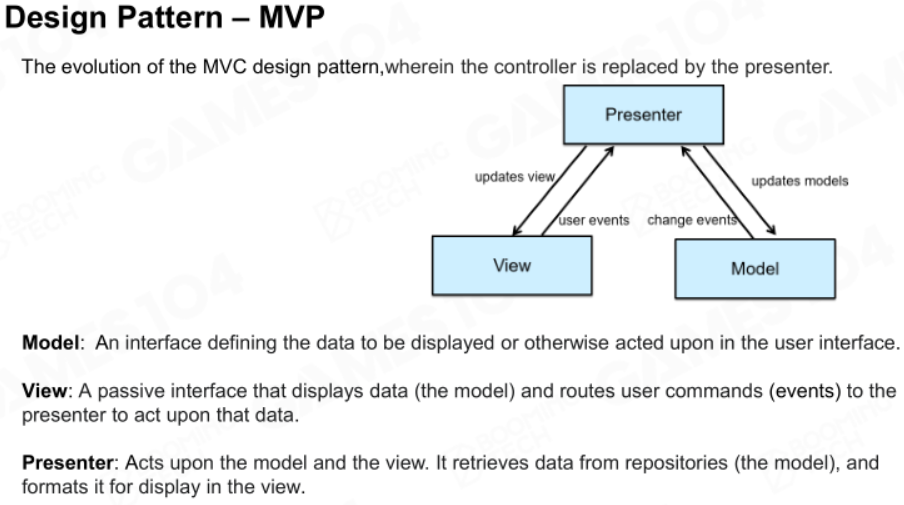
MVP
是MVC设计模式的提升,让View不再依赖Model,只进行数据展示,将View和Model之间的联系交给Presenter。这不可避免地增加了Presenter的复杂度。
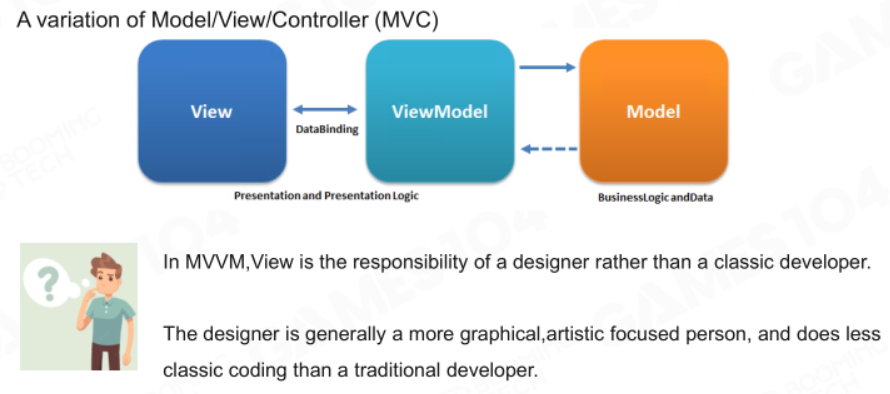
MVVM
是当下较为流行的设计模式,在View中不再实现获取数据的逻辑,只是单纯实现如何展示数据,并通过DataBinding向ViewModel获取数据。
如下图所示,原始的数据在Model中,ViewModel将Model中的数据拿过来,并封装为View接受的数据,View则通过Binding自动呈现ViewModel中封装好的数据。
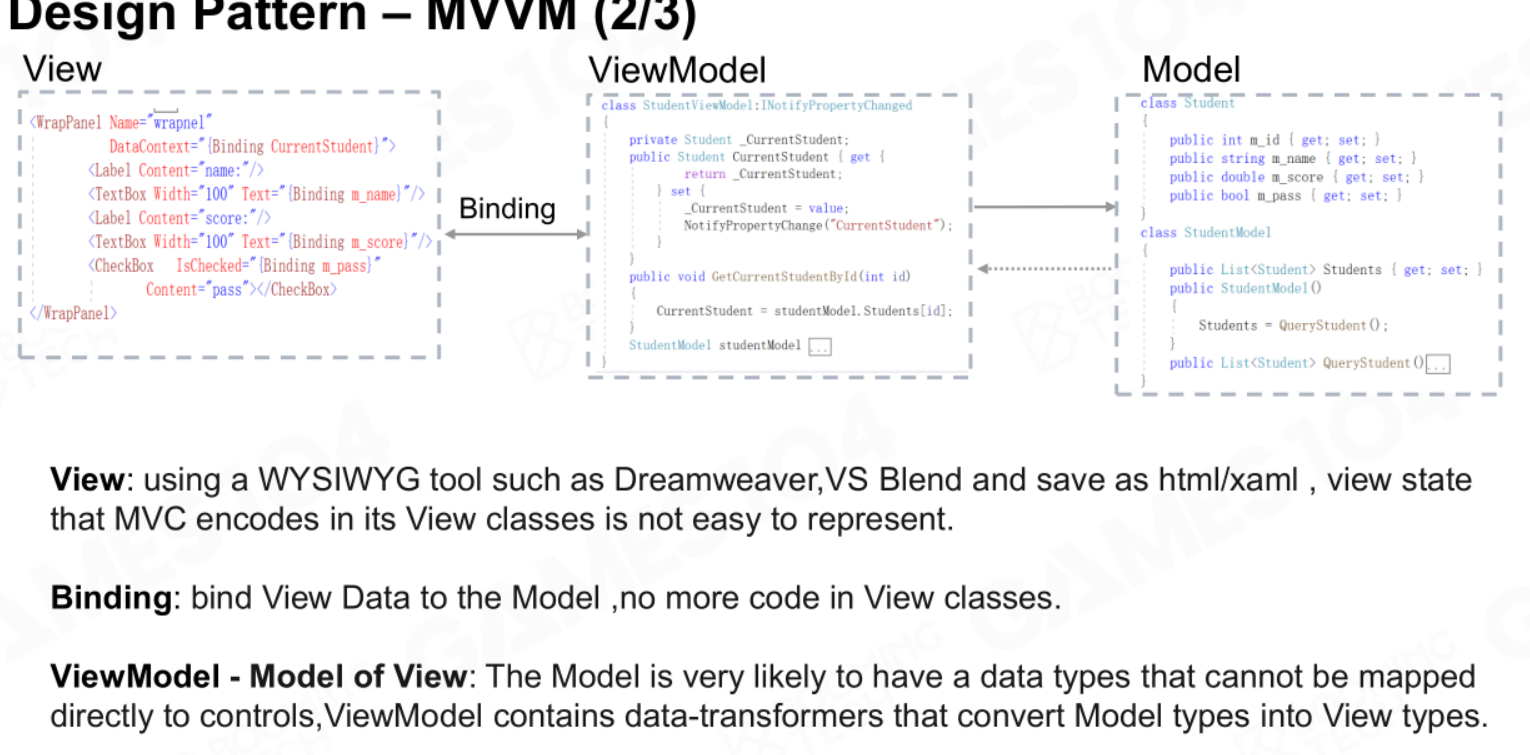
使用MVVM的好处为:
- 易于独立开发;
- 容易维护和测试;
- 容易重用组件;
使用MVVM的缺点为:
- 对于简单UI,使用MVVM相当于大炮打蚊子;
- DataBinding不好Debug。
游戏资产的管理
资产的存储
文本文件
可以将数据按一定结构/格式存储到文本文件中,例如TXT,Json,Yaml,Xml。这种直观可读的方式方便人们Debug,但占用可能会大一些。

二进制文件
也能将数据存储为二进制字节流,这样将会大大减少存储空间,且减少了Parsing阶段的时间。

对比
对于文本文件,直接以<Key, Value>形式按要求存储;对于二进制文件,先在头部存储该资产的组织情况,然后单独存储对应数据,到时候读取就先在头部查表,然后去相应位置读取。

大小端序
还有个让人头疼的问题就是大小端序,在不同的架构下,数据读取的顺序还不一样。因此,如果引擎是跨平台的,这个问题就是不可避免的。

资产的重复使用
游戏引擎必不可少的一个功能就是提供资产的重复使用,这样可以节省不必要消耗内存空间。
资产引用
这个是引擎工具链的核心底层逻辑,将离散但有关联的资产进行整合, 使用引用将它们关联在一起。

资产实例化
要想实现资产的重复使用,还得让游戏引擎支持数据的实例化。它可以用一个单独的资产在场景中生成数个独立的对象。

实现简单的实例化还不够,对于实例化后的每一个对象,还得提供“变种”能力。该能力可以让实例化对象随时更改它的属性,例如更改贴图。
一种较为简单的方式是,给它专门复制一份数据,供它修改。

但这种操作的弊端也很明显:
- 文件操作比较繁琐;
- 在源资产上的变化无法同步到复制后的资产。
因此应该使用 数据继承(Data Inheritance)技术来创造变种实例。类似于C++中类的继承,数据也可以被继承,然后只需要重写相应成员数据即可实现创造变种实例。
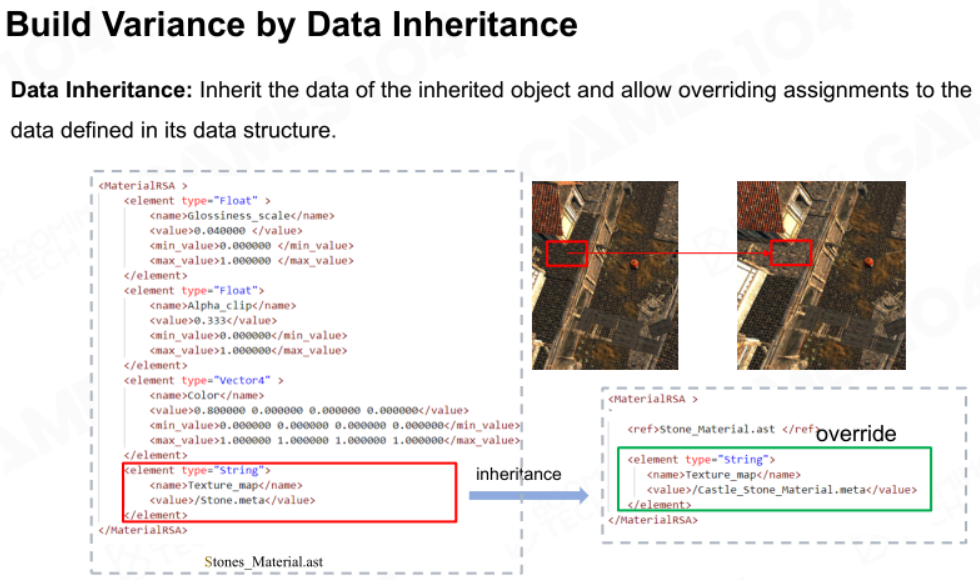
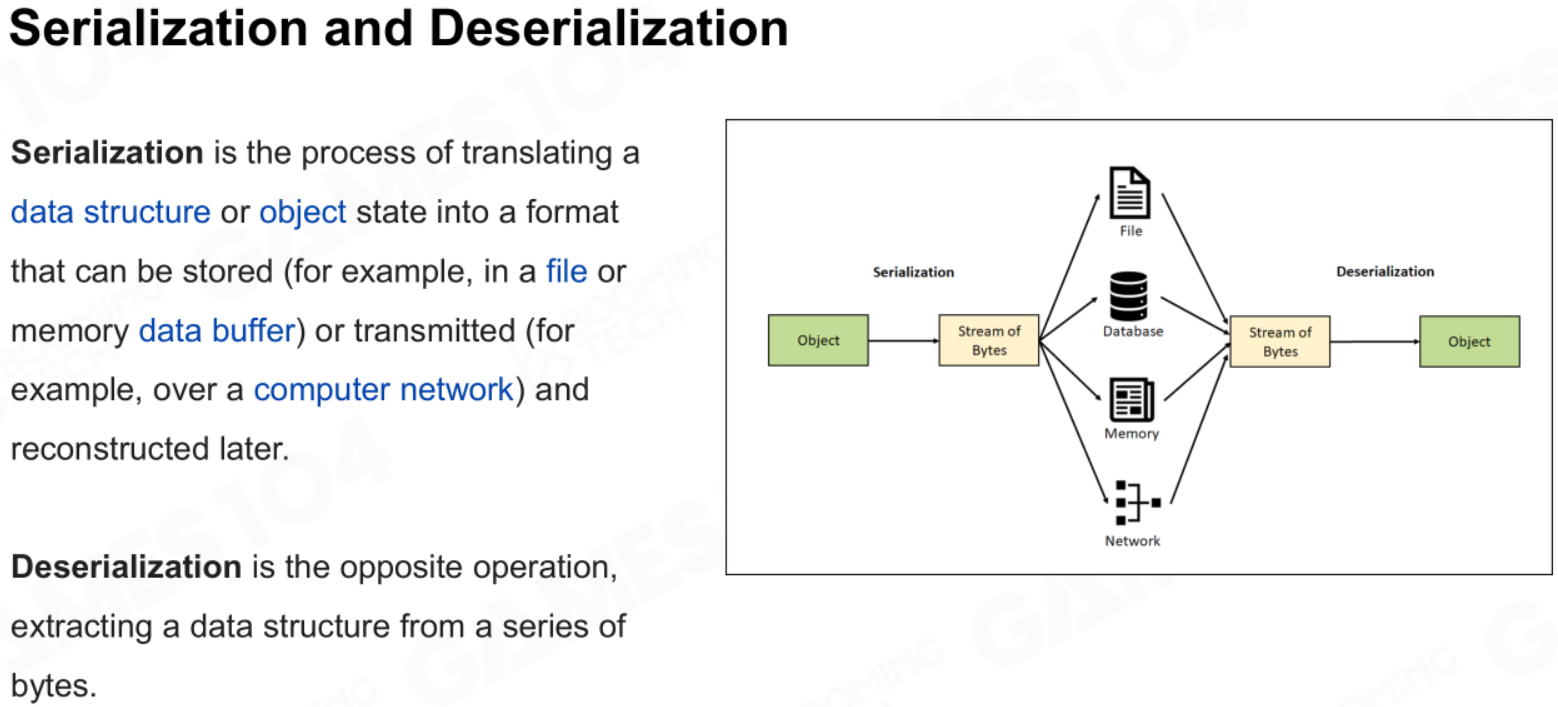
序列化和反序列化
可以将一个对象 序列化(Serialization) 为一个特定的存储对象(如一个文件、一块内存、一个数据库条目等);之后通过 反序列化(Deserialization)将这个存储对象读取并转换为原来的对象。
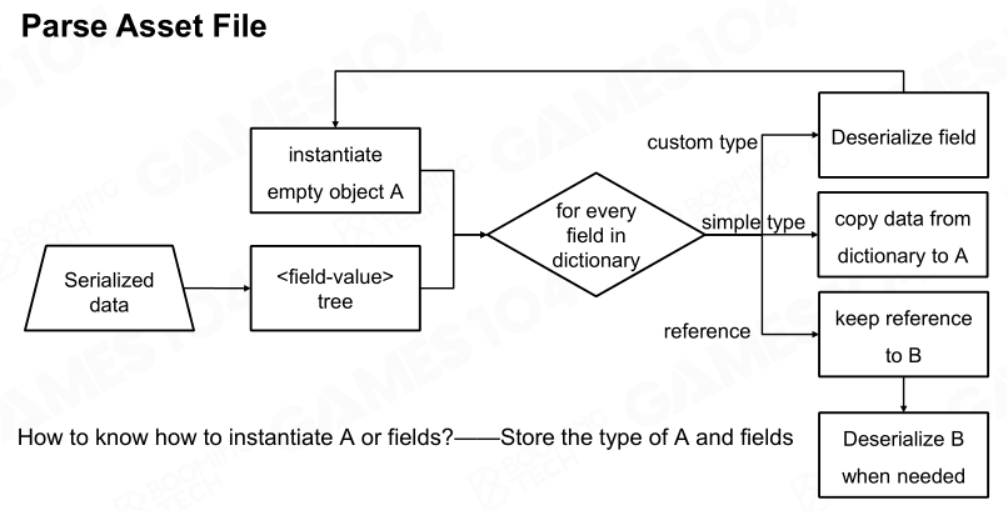
通过反序列化加载资产
要想加载资产,得先转换资产文件.asset,从中了解这个资产的组织情况,以及需要依赖其他哪些资源。在不知道资产的组织情况下,盲目加载所有资源是不合理的,需要在了解组资产组织情况后,才会加载它需要的资源到对应的位置。
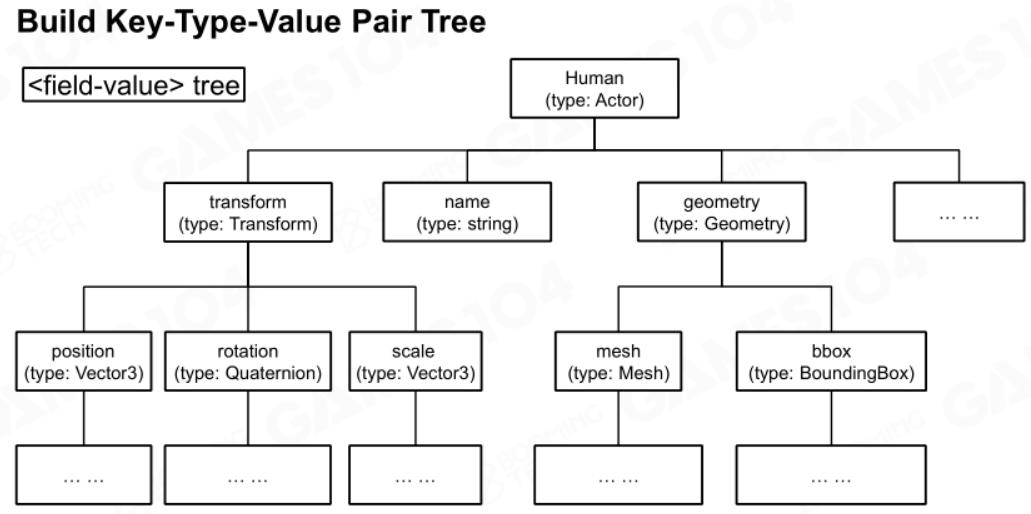
例如下图就是一个资产的依赖层级树:
资产的版本兼容
还需要实现资产的向上&向下兼容,新版本的工具可以加载旧版本创建的资产,旧版本的工具能尽量加载新版本的资源,实现后者非常困难。
成员的添加/删除问题
如下图所示,可能会给资源新增一个成员,也可能会删除一个成员,那该如何读取旧数据。

简单粗暴的解决方法是给资产添加“版本号”这一属性,然后根据不同的版本号写不同的逻辑。缺点也是显而易见的,就是维护难度随时间增长。

Google的解决方法(Protocol Buffers)是给每个数据成员提供一个UID,成员每被修改一次,UID就会自增一次。
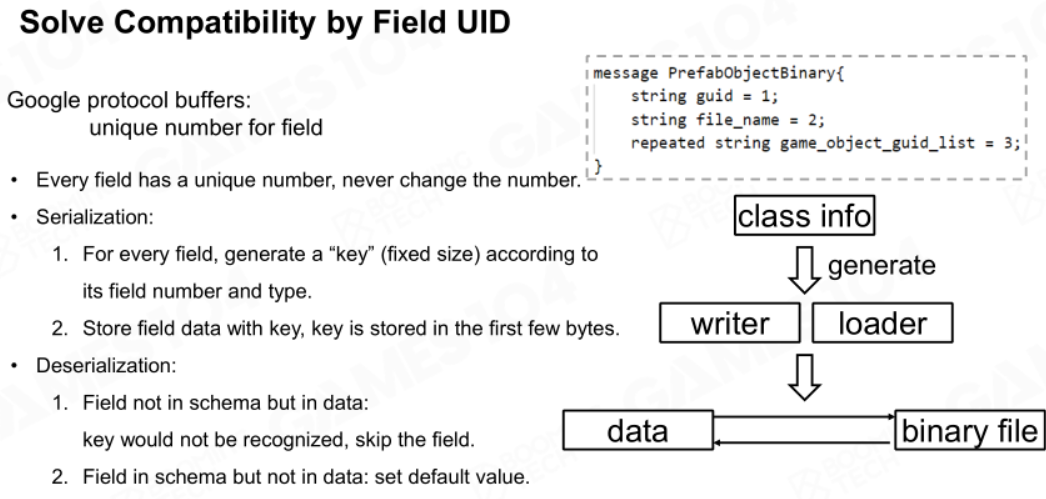
增强工具链的健壮性
游戏引擎工具链对健壮性的要求很高,一些需要实现的特点有:
- 撤销&重做
- 崩溃恢复
命令
用户在编辑器上的所有操作都能被抽象为一些原子命令,游戏引擎会将命令定时存储在磁盘上,方便撤销和重做。
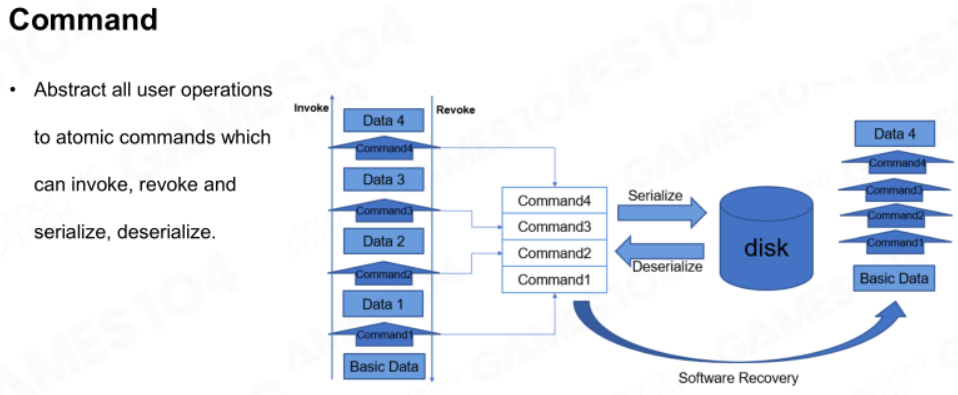
通用抽象
通用的命令抽象定义如下,需要有UID,数据,执行操作Invoke(),撤销操作Revoke(),以及用于存储的序列化和反序列化:

UID是唯一且累加的,方便了解命令的执行次序;

序列化和反序列化函数要求存储的数据自身支持序列化和反序列化;

关键命令
要具象化一些命令,就得实现上面提到的命令抽象接口。常用的关键命令有如下三个:
添加 Add:创建一个对象。
- Data:通常是运行时实例的一个拷贝;
- Invoke():用Data创建一个运行时实例;
- Revoke():删除该运行时实例;
删除 Delete:删除一个对象。
- Data:通常是运行时实例的一个拷贝;
- Invoke():删除该运行时实例;
- Revoke():用Data创建一个运行时实例;
更新 Update:改变一个对象中的一个值、
- Data:通常是运行时实例中,被编辑过的属性名和对应值(修改前和修改后的);
- Invoke():将运行时实例中被编辑的属性设置为修改后的新值;
- Revoke():将运行时实例中被编辑的属性设置为修改前的旧值;
如何制作工具链
工具链,顾名思义最关键的就是“链”,它将许多看似没有关联的工具联系起来,工具A的数据输出可以变成工具B的输入等。
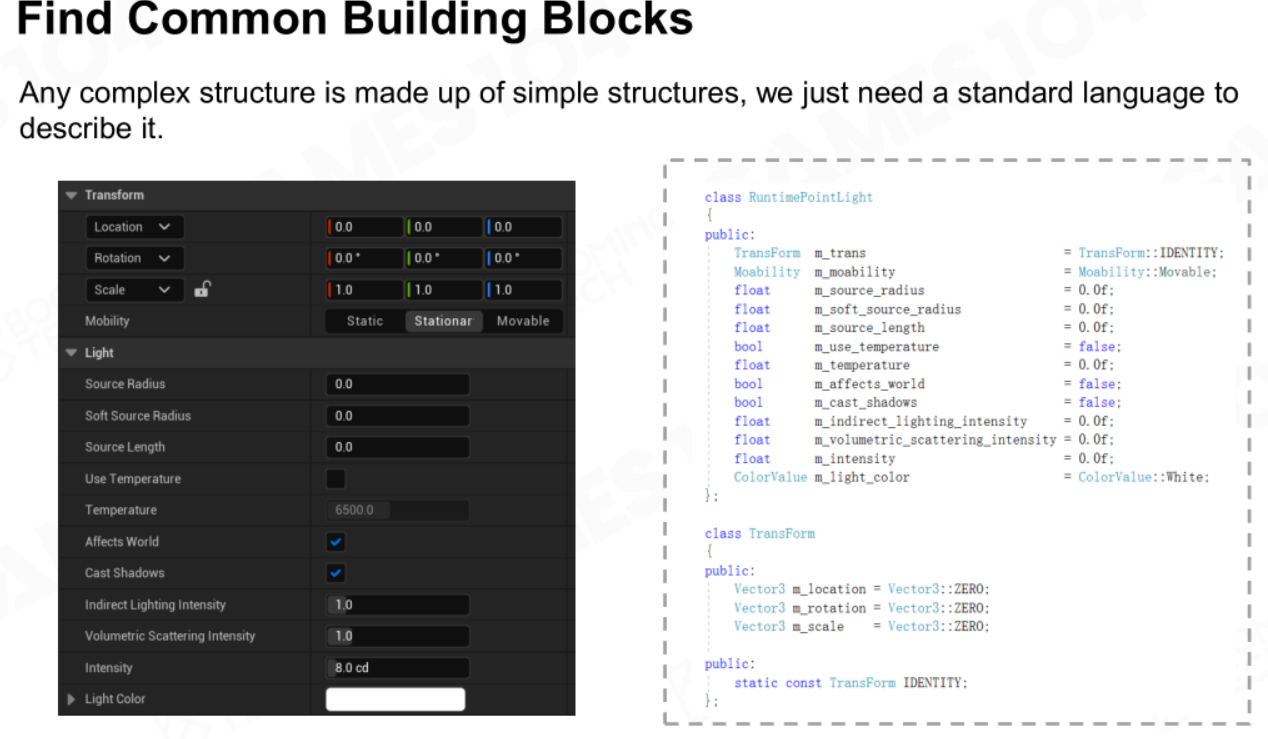
找到通用构建块
任何复杂的结构都由一些简单的结构组成,而部分简单结构又是通用的。例如下图中点光源的描述,需要SRT变换信息,而Transform刚好由SRT变换信息组成,于是便能用Transform代替三个单独的SRT变换信息存储。
数据构成-Schema
可以用数据构成来描述当前系统的数据是如何组织的。常用的数据构成如下:
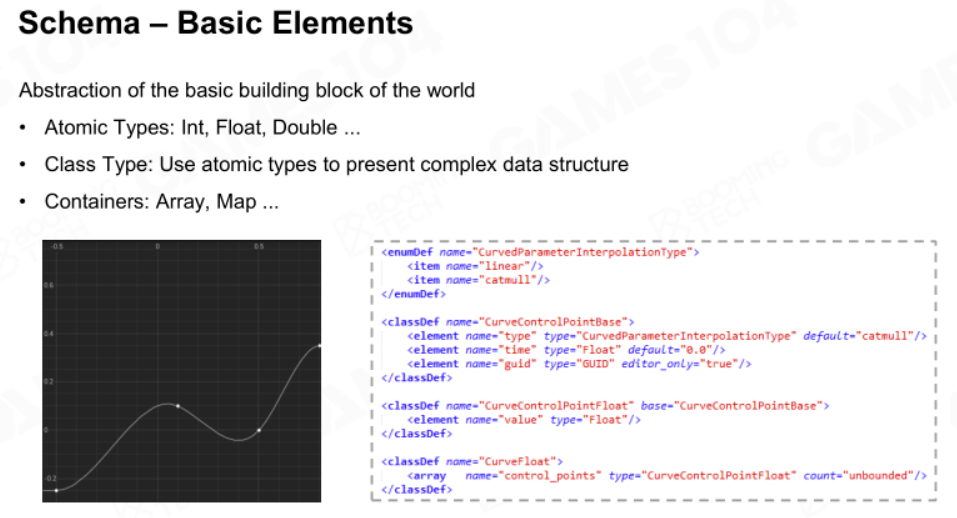
基础元素
数据构成要求我们要用最小不可分割的原子数据来构成一些上层数据结构。例如要表达一个曲线,就需要将它看作数个控制点的集合,而一个控制点则包含一些曲线属性的集合。
继承
一些数据结构还存在继承的概念,子结构可以复用父结构的数据,并添加新的数据。

数据引用
数据还得是能被引用的,例如3D材质的定义需要一个2D材质引用数组。

代码定义
有两种定义Schema的方法,一种是在单独的文件中编写;另外一种则是在源代码中通过反射宏定义。个人推荐后者。

它们的优缺点如下:

数据的要求
对于引擎的数据,需要满足三方面的要求:SSD、HHD的存储要求;人的可视化要求;CPU、GPU能够处理的要求。
运行时要求
要求数据能被高效读,计算。

存储要求
要求数据能被高效写,占用空间小。
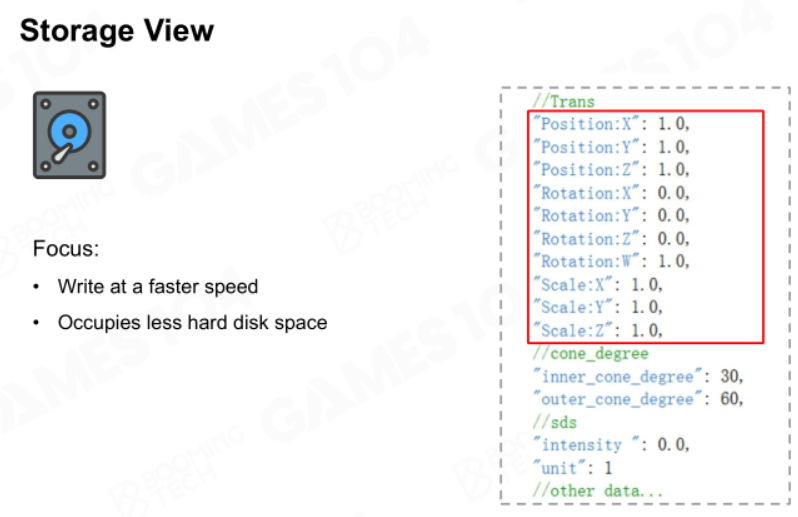
用户要求
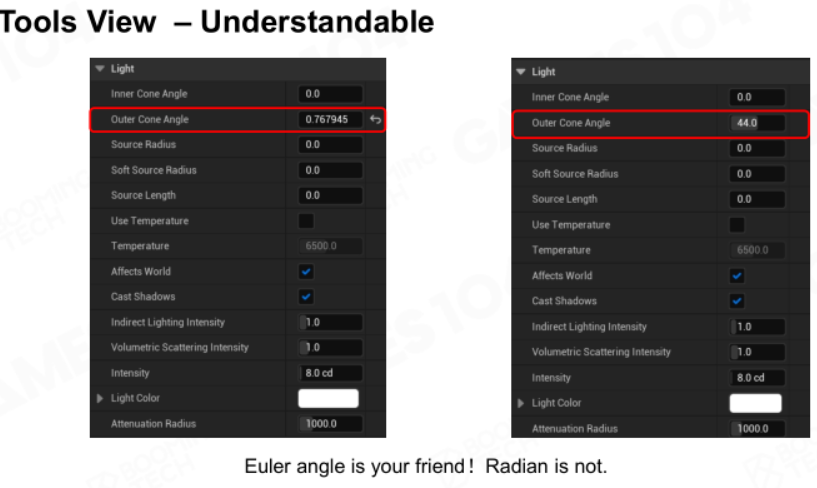
要求数据能被易于理解,例如冷冰冰的RGB三个小数无法理解,但加上相应色条就好理解了。

还有角度制和弧度制,对于计算机来说弧度制好理解,对于人来说角度制好理解。
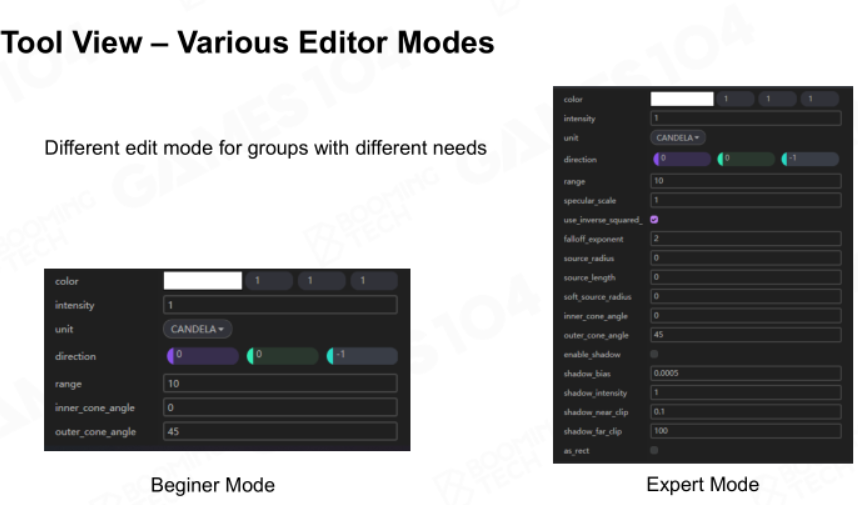
此外,还得为新手和老手做区分,将一些难以理解的项用“Advanced”包括起来:
所见即所得原则
制作工具链还要遵循所见即所得原则(What You See is What You Get,WYSIWYG)。对于艺术家来说,他看到的就是一些材质和打光的设置;对于策划来说,他看到的就是一些能快速制作关卡原型的工具。
工具链架构
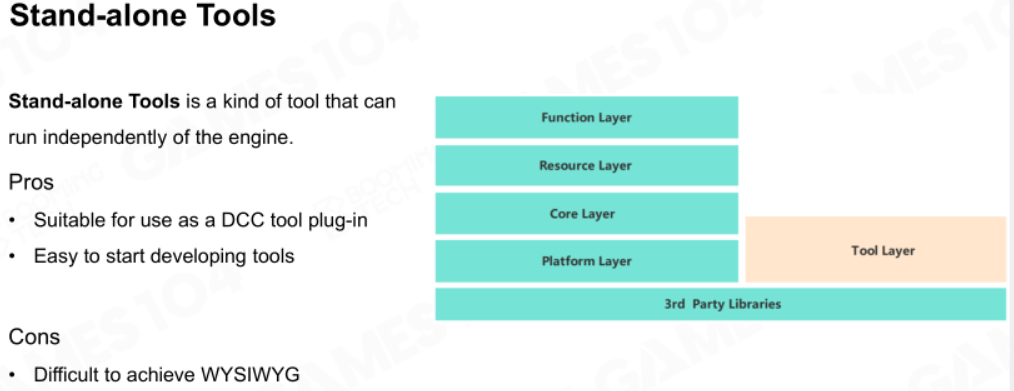
独立架构
早期的工具链是相对引擎独立的,对DCC创作来说很方便,但难以遵循所见即所得原则。
引擎上架构
现代游戏引擎则把工具链直接架构在引擎层上,通过工具编辑好的内容直接在游戏预览中可见,实现真正的所见即所得。

首先是编辑器模式,该模式允许我们编辑和实时预览场景信息。
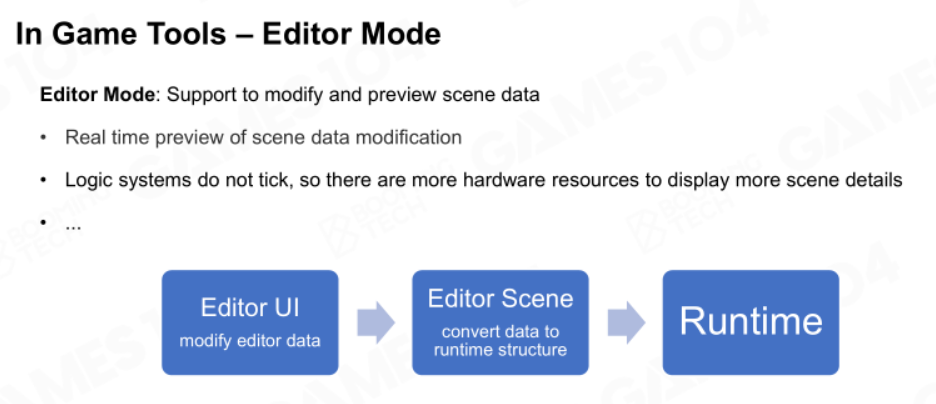
然后是PIE(Play In Editor)模式,编辑器编辑好关卡后,可以直接点击播放键,然后在编辑器里开始玩游戏。

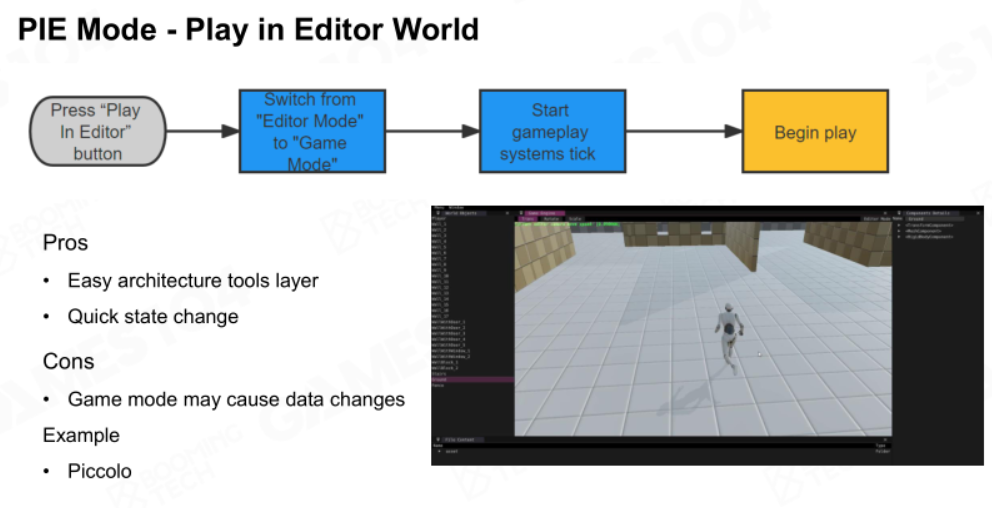
PIE的实现主要有两种:
在编辑器世界中游玩:直接在编辑器编辑好的世界下游玩。
![]()
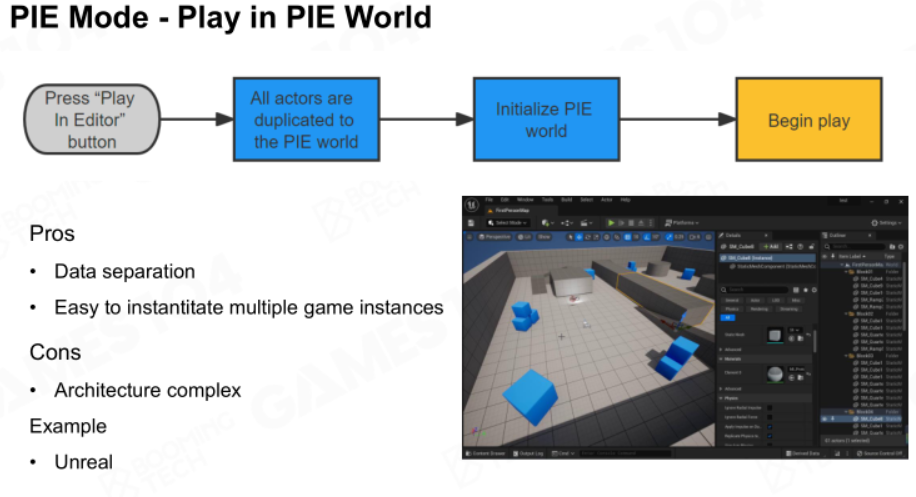
在PIE世界中游玩:先将编辑器编辑好的世界进行拷贝,然后在拷贝的世界下游玩。
![]()
引擎插件
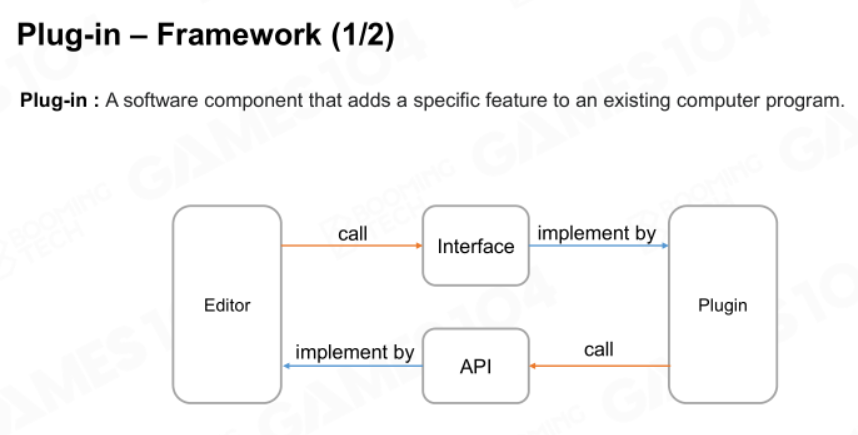
在游戏引擎的基础上,还需要添加一些额外功能/工具的话,就需要通过编写插件来完成。支持插件编写是引擎可拓展性能力的验证。
架构
引擎编辑器得提供特定的接口给插件开发者,让他进行实现和定制。
实现好的插件通过插件管理者进行统一管理,例如加载和卸载插件。

对引擎的要求
尽可能的将引擎的功能API化。
参考资料
- GAMES104 (boomingtech.com)
待阅读的资料
- Tools Tutorial Day: A Tale of Three Data Schemas, Ludovic Chabant, GDC2018
- Creating a Tools Pipeline for ‘Horizon: Zero Dawn’, Dan Sumaili, Sander van der Steen, GDC 2017
- Unreal Engine UProperties
- Command Pattern
- Unreal Plugins
- Model–view–controller
- MVC 1
- MVC 2
- Benefits and Drawbacks of MVC Architecture
- Model–view–presenter
- Model–view–viewmodel