01 - 游戏引擎中的渲染实践
本文主要介绍了一些游戏渲染相关的基础知识,包括渲染系统的对象,GPU初步,可渲染物体等内容。
渲染系统概述
在GAMES101中入门了图形学(个人感觉入了半个门),提到实时渲染(30FPS),交互渲染(10FPS)离线渲染等渲染方式。在游戏引擎中,主要关注一些图形学算法的准确性。
学术界和工业界还是不一样的,游戏引擎是工业界的结晶,需要不断更新迭代,而一些图形学理论可能十几年才更新一次,两者差别很大。
游戏渲染所面临的挑战
- 同时处理一大堆物体及其效果,不同物体使用不同渲染算法,还要进行后处理等。十分复杂。
- 在现代硬件基础上渲染(设备不是最理想的),算法需要针对硬件进行深度适配和优化。
- 游戏场景千变万化,对画面/分辨率要求越来越高,但帧率必须要求稳定,否则玩家体验会差。
- 如何全面利用好CPU,但同时为引擎的其他系统留下CPU资源。
大概内容
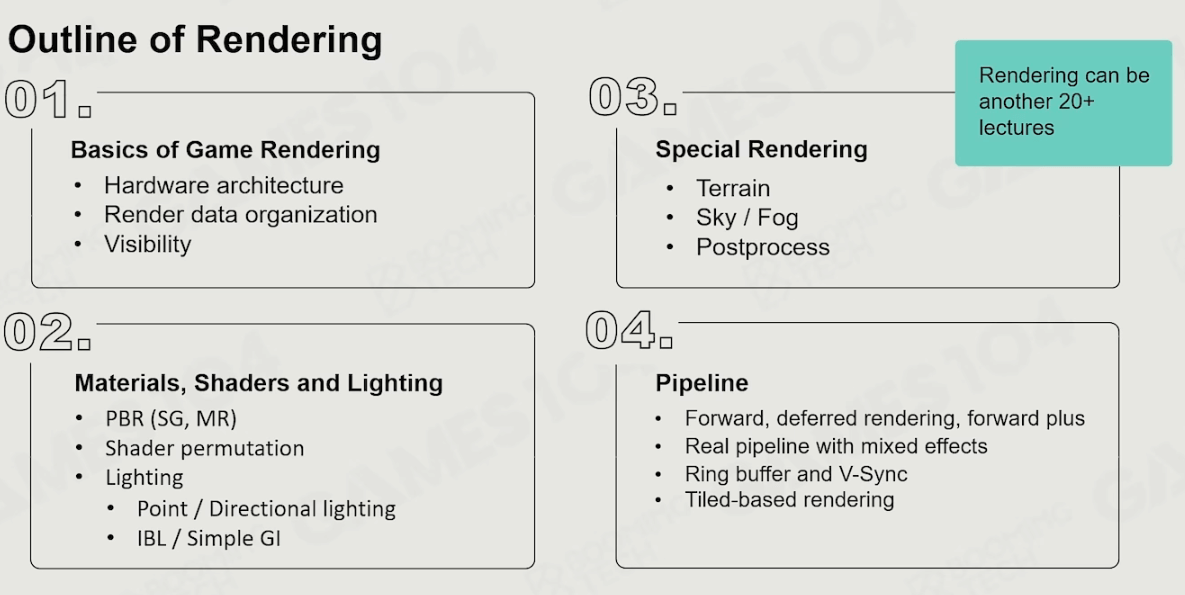
如图,主要分为了四部分(也有一些高级知识没有加进去)。
渲染系统组成
渲染管线及其数据
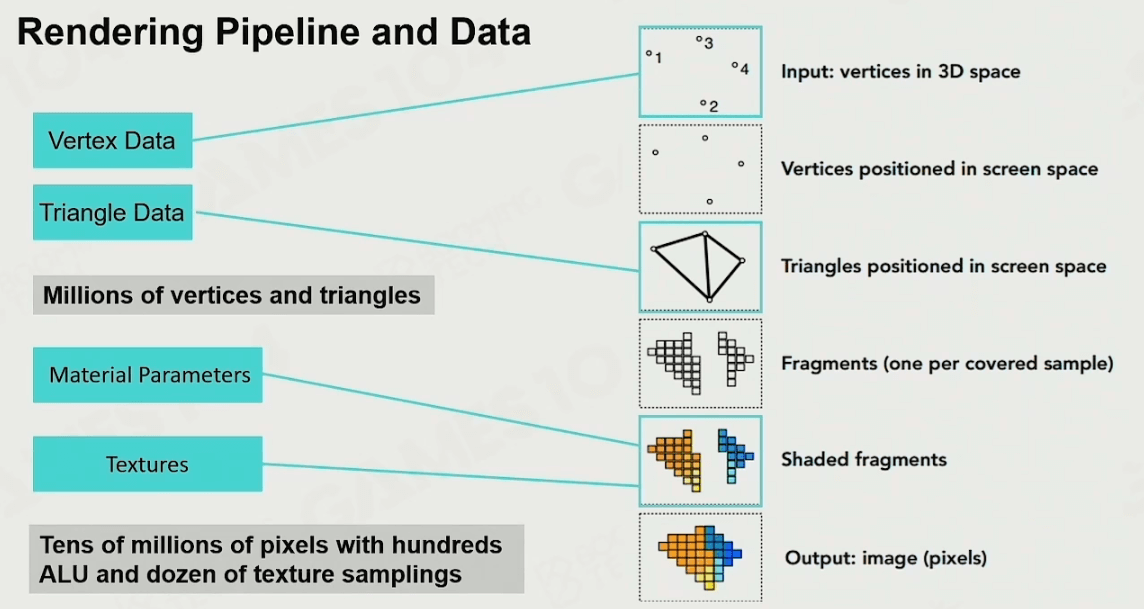
各种各样成千上万的顶点数据经过渲染管线,成为一个个颜色不同的像素点,构成游戏世界美丽的景色。
计算
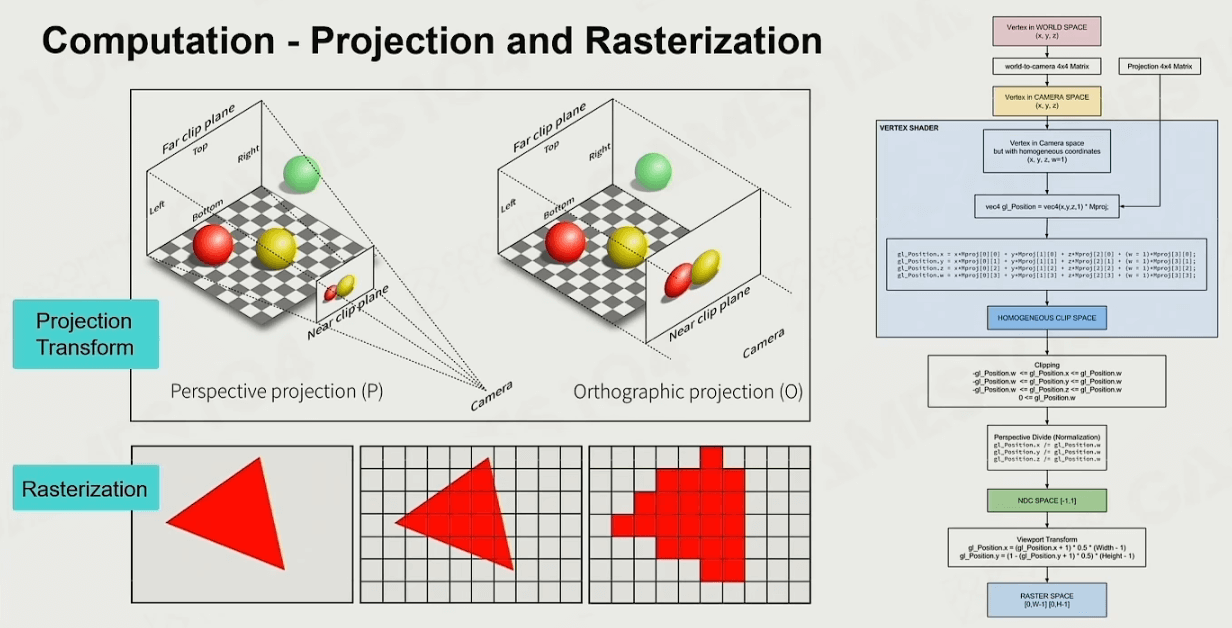

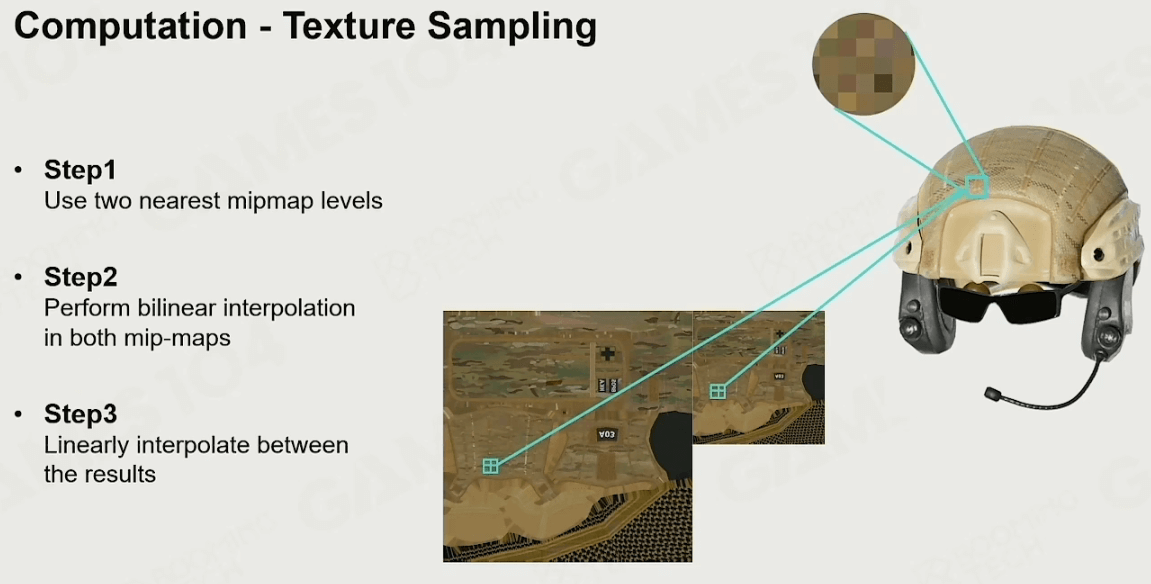
渲染系统还要做很多方面的计算,如上方提到的投影和光栅化、着色、材质绑定等,这些计算量很大,需要GPU来帮我们完成。
了解GPU

GPU,全称为 Graphic Process Unit,就是显卡。随着显卡的发展,渲染技术也随之突飞猛进,要想了解好游戏引擎的渲染系统,也必须对GPU架构有一定的了解。
SIMD和SIMT
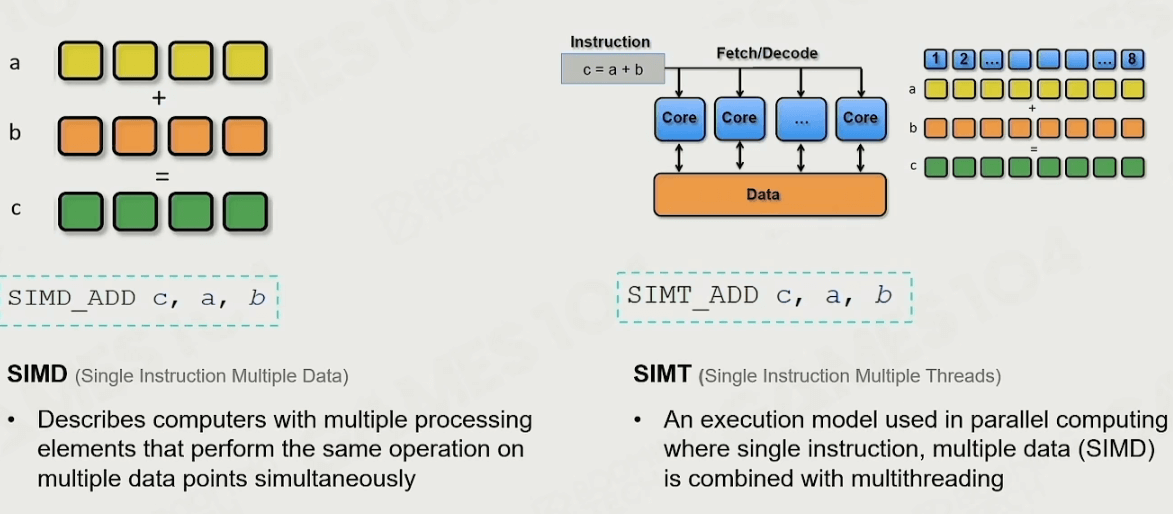
SIMD,即单指令多次运算,一个指令可以完成四个加法/减法,是做大量运算时的好帮手。
SIMT,即单指令多线程运算,一个指令可以让多个线程执行,如果再配合SIMD,那么计算效率会大大提升。
有了这两个好帮手,GPU上渲染相关的计算能力会远超过CPU。
现代GPU架构
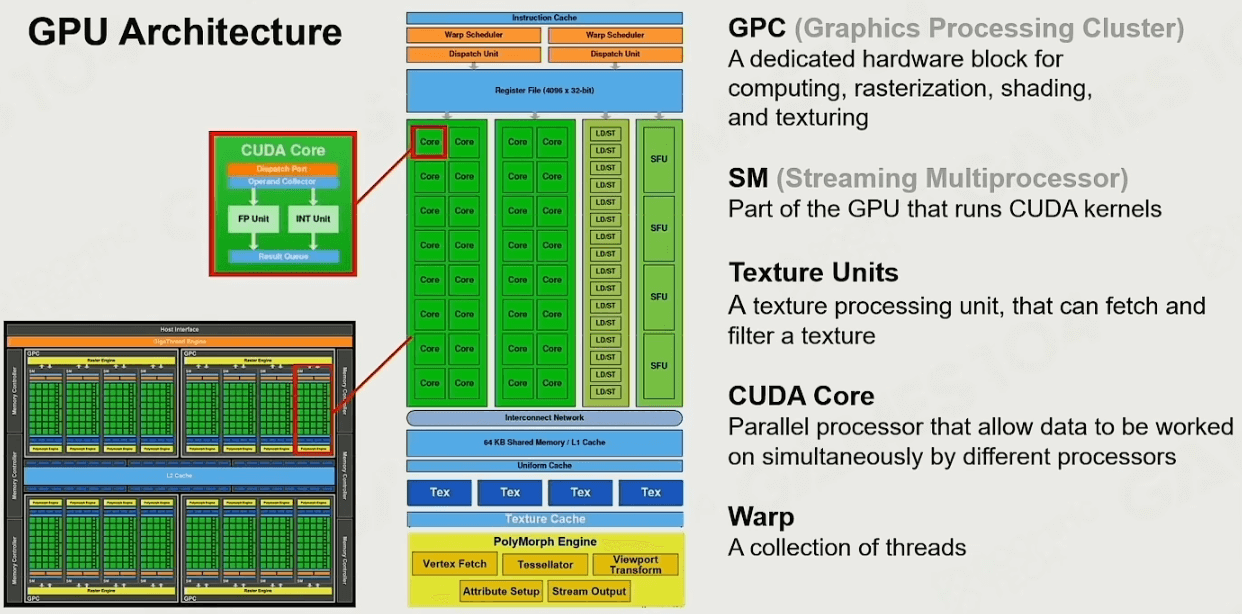
以Fermi架构为例,GPU主要有以下几个部件:
- GPC:图形处理集群,完成计算、光栅化、着色和材质等计算任务。整个 GPU 有多个 GPC(图形处理集群),单个GPC包含一个光栅引擎(Raster Engine),四个 SM(流式多处理器)。
- SM:流式多处理器,每个SM有32 个CUDA 内核,分在两条 lane 上。
- CUDA内核:做大量数学运算,给SM指令,所有CUDA内核就会开始运算。
- 等等…
GPU的各个组件间存在瓶颈(Bounds),如果不好好利用/平衡它们的话,就可能出现以下性能(Performance)问题:
- 内存局限:内存跟不上其他部件的运算
- ALU局限:运算跟不上其他部件的要求
- ……
CPU和GPU间的数据流
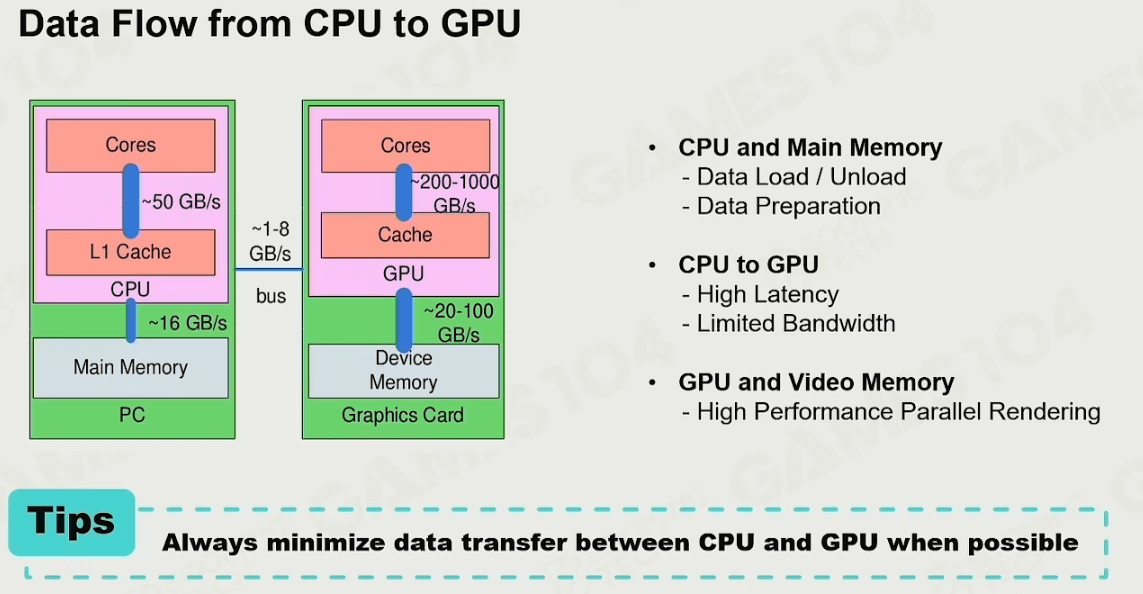
由于CPU和GPU性能/架构不同,在他们身上读取数据的速度也不同。为了避免出现“卡帧”等现象,应该 尽量只让数据从CPU送到GPU 。
Cache的作用
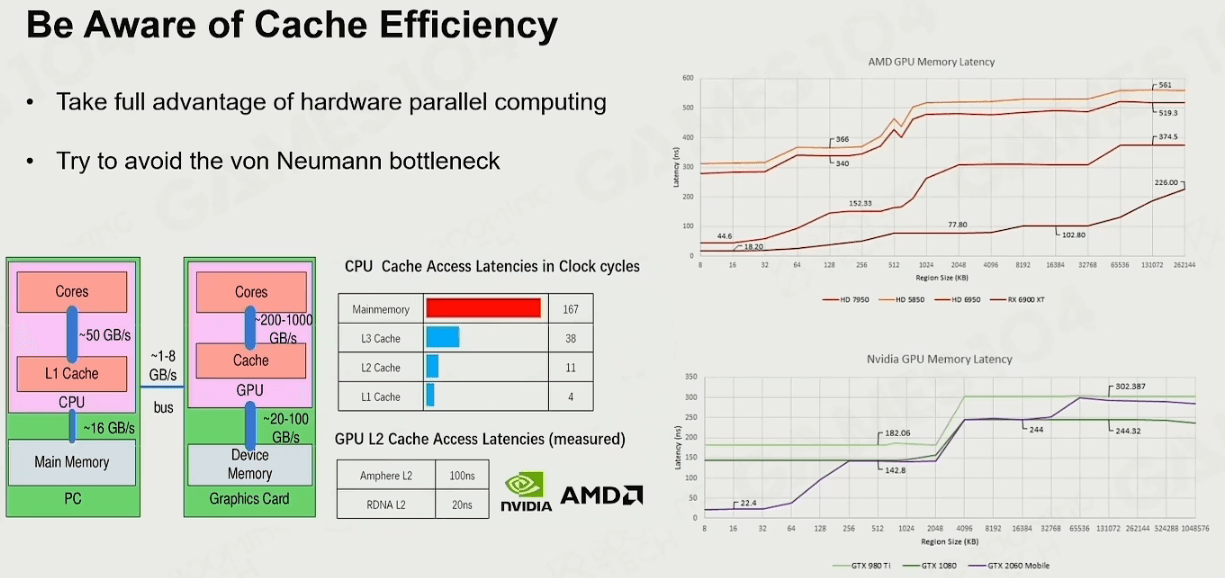
让数据尽量集中起来,容易出现Catch Hit,省去读硬盘耗费大量时间。
随机应变的游戏引擎
对于不同的硬件和架构,游戏引擎要针对他们进行随机应变。例如DX12,XBox主机的UMA架构,移动端的分块渲染技术等。
可绘制物体(Renderable)
在Mesh Render组件中,有一个可绘制物体,是绘制系统中核心的数据对象。
基本组成
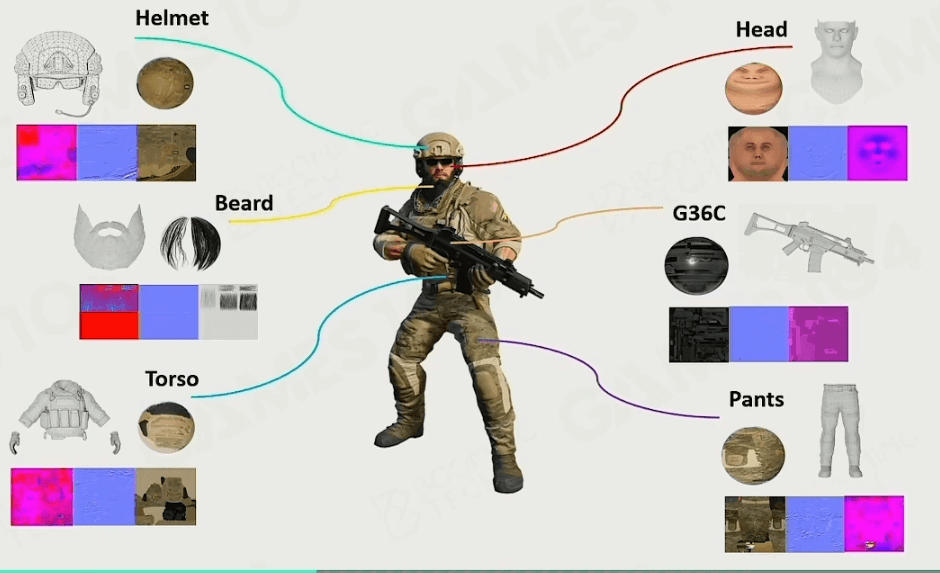
以一个人物为例,可绘制物体包括它的各种贴图,材质和模型等。接下来详细说说如何去描述一个可绘制物体。
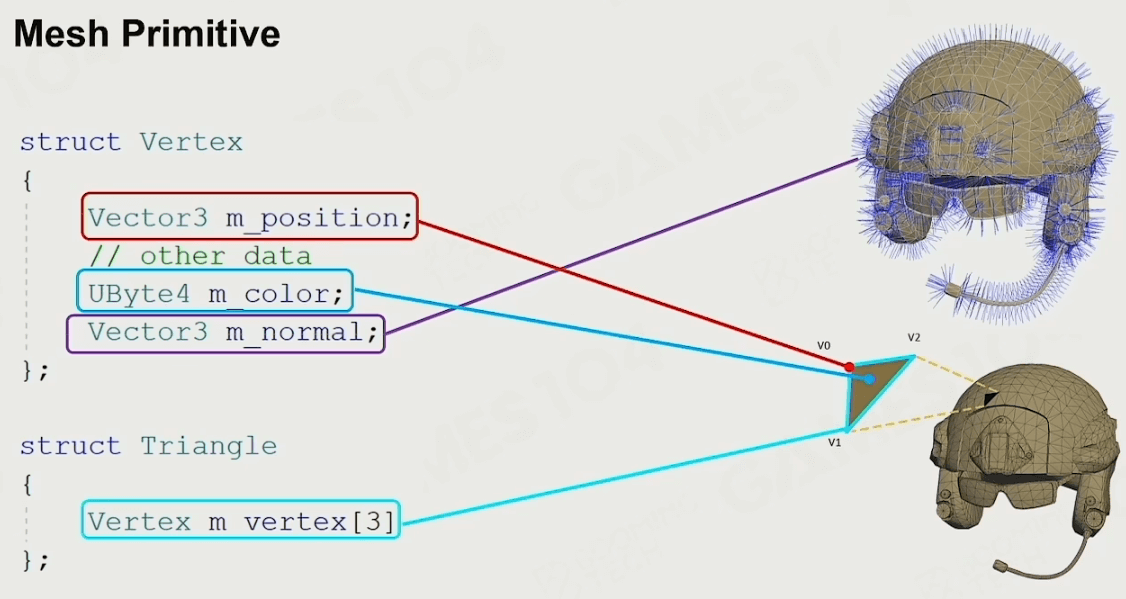
首先得描述一下该物体的形状数据(Mesh),如图,我们需要这种数据结构来存储Mesh每一个顶点的信息和每一个三角形的信息。
当然,像这样存储就会很麻烦,不如将所有顶点信息存储到一起,使用索引来使用它们,节省存储空间:
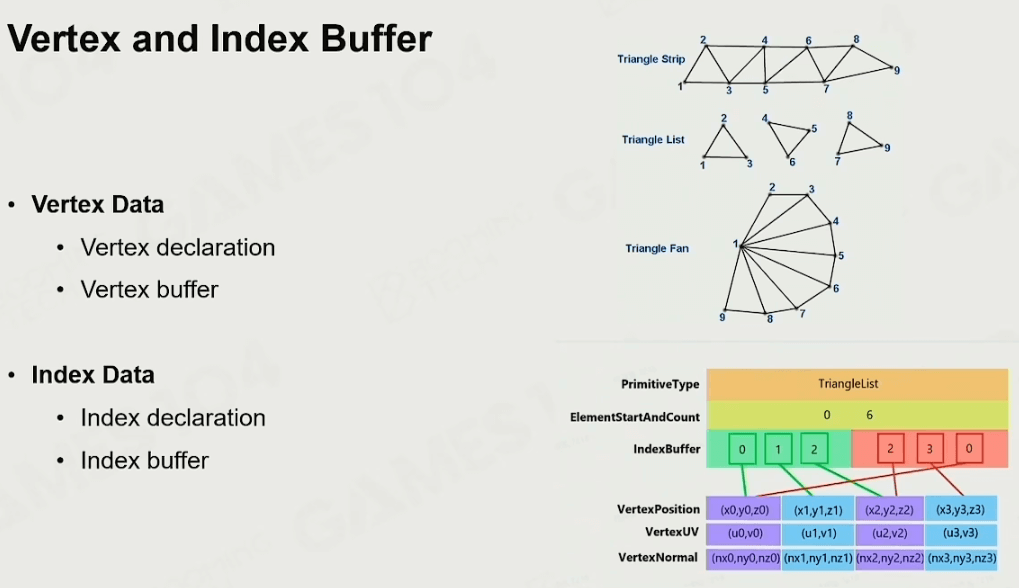
在早期游戏引擎中,为了提高效率和节省空间,常常会想法儿把三角形组织成上图Triangle Strip的样子,可以顺序地读取三角形,加大缓存命中,并且顶点索引也没必要存了。
对于顶点法线的存储,推荐 每个顶点单独定义它的法线方向,防止由于硬表面产生的bug。
知道物体的形状后,接下来就得描述物体的材质(Material)了:

这些材质决定了该物体长什么样子,例如Phong模型、PBR模型等。
要想让材质变得更加细节,还得在上面附加纹理(Texture):

纹理也是材质的一种很重要的表达方式。
最后,还要编写一小段着色器(Shader)代码,将上面这些东西组织起来:

绘制流程
准备好模型资产后,进行绘制前,要让这些资产通过一系列变换,确保它们能被正确渲染在屏幕空间:
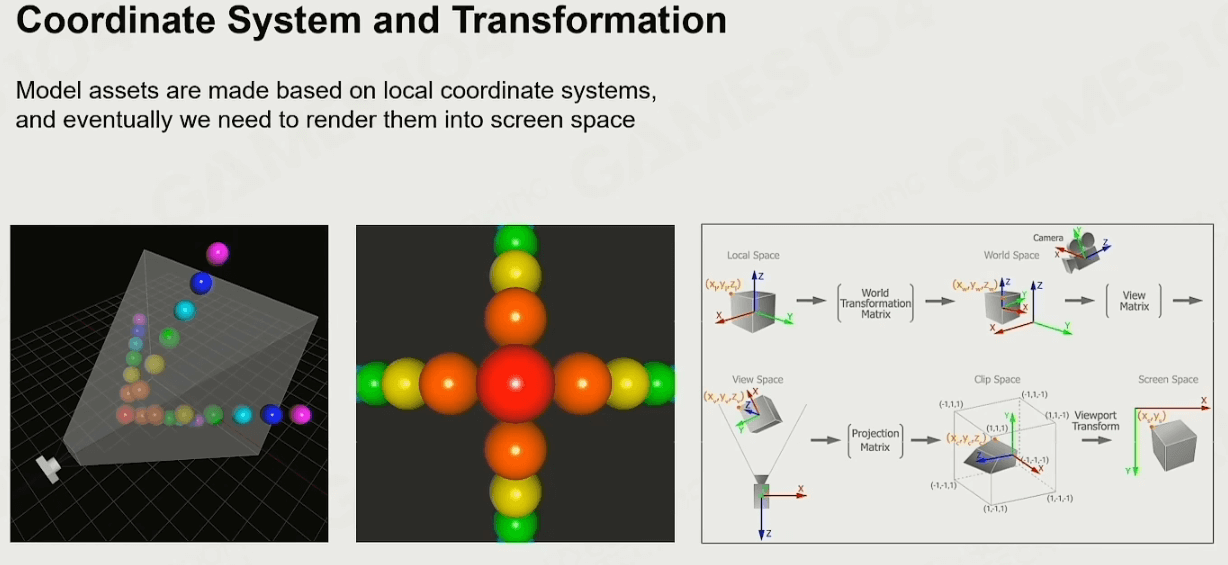
接下来就能将资产信息给显卡进行绘制了:
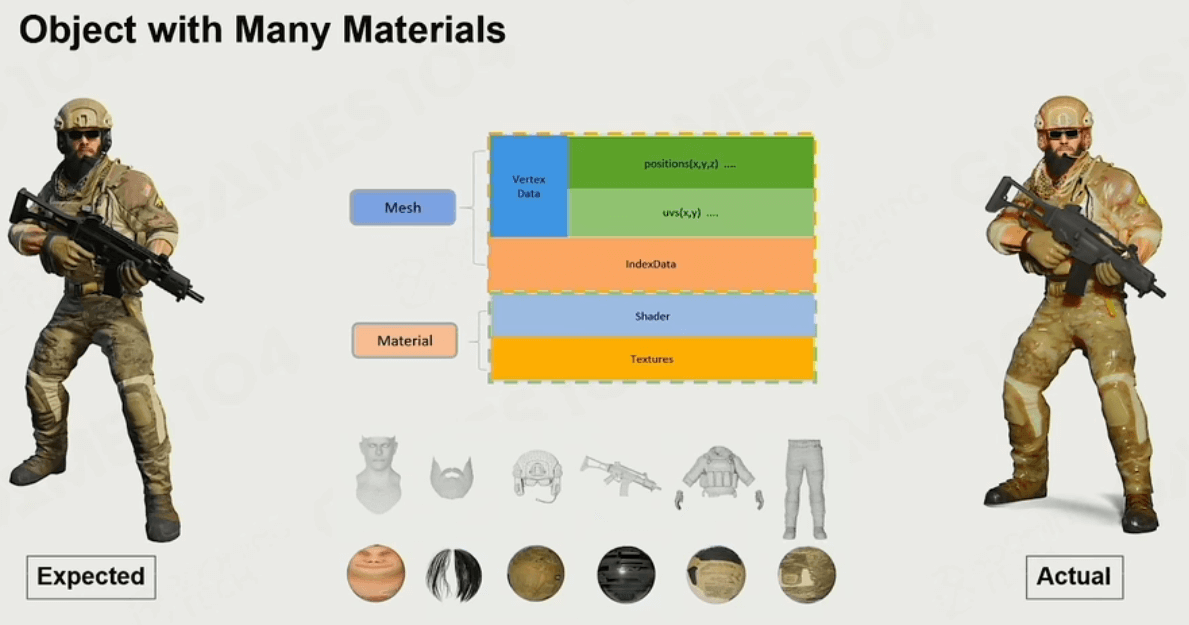
但是渲染出来的结果却不符合预期,这是因为我们的模型用的是整体上的材质(纹理+着色器),各个部件缺少一定的细节。
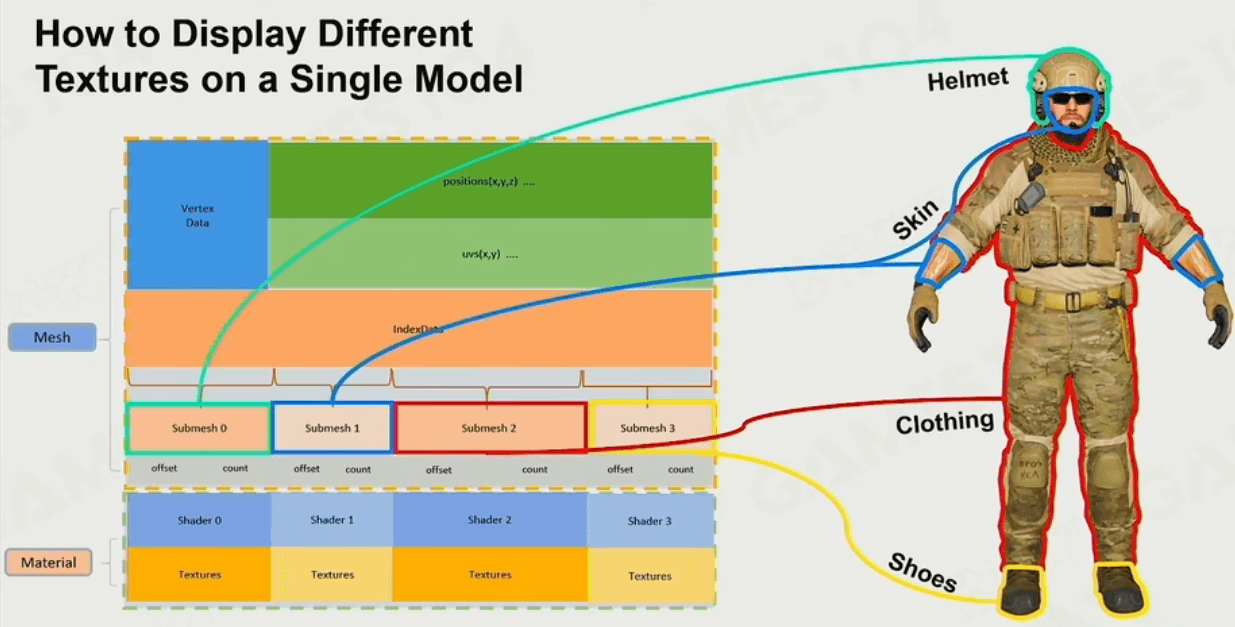
于是引入现代引擎中常用的Submesh,将一个模型分成好几个Submesh,每个Submesh使用各自的材质,更有细节感:
可复用性
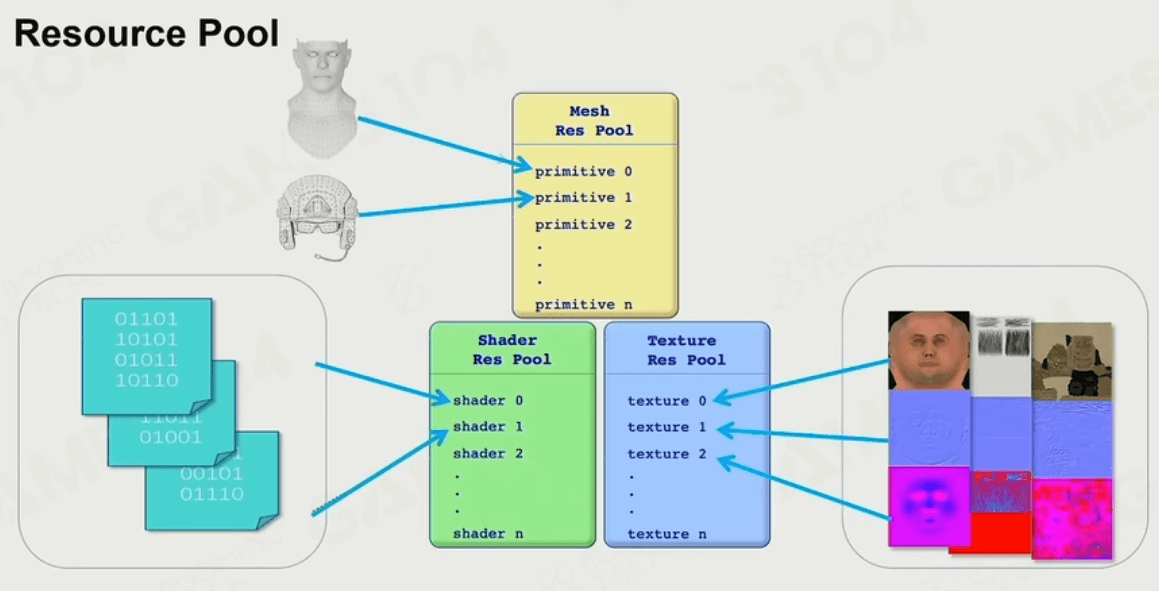
在现代游戏引擎中,为了提高资源的可复用性,减少不必要的存储消耗,会使用 资源池(Resource Pool)来管理可绘制物体:
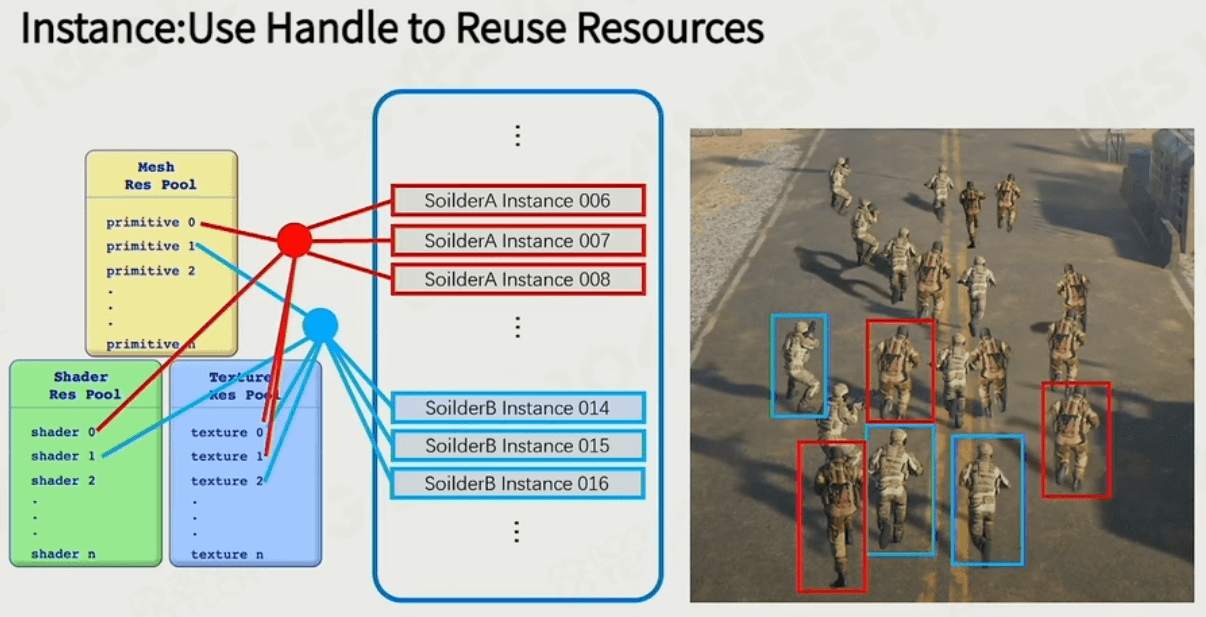
游戏中生成的实例可以复用这些资源:
效率优化
考虑到显卡不喜欢我们在渲染物体时老切换材质,因为这样做会降低它的运算速度,我们可以 按材质将Submesh排序,让显卡快速渲染它们。

除此之外,为了快速渲染出一大片草地/森林,可以用 GPU批渲染(Batch Rendering) 技术完成此任务。
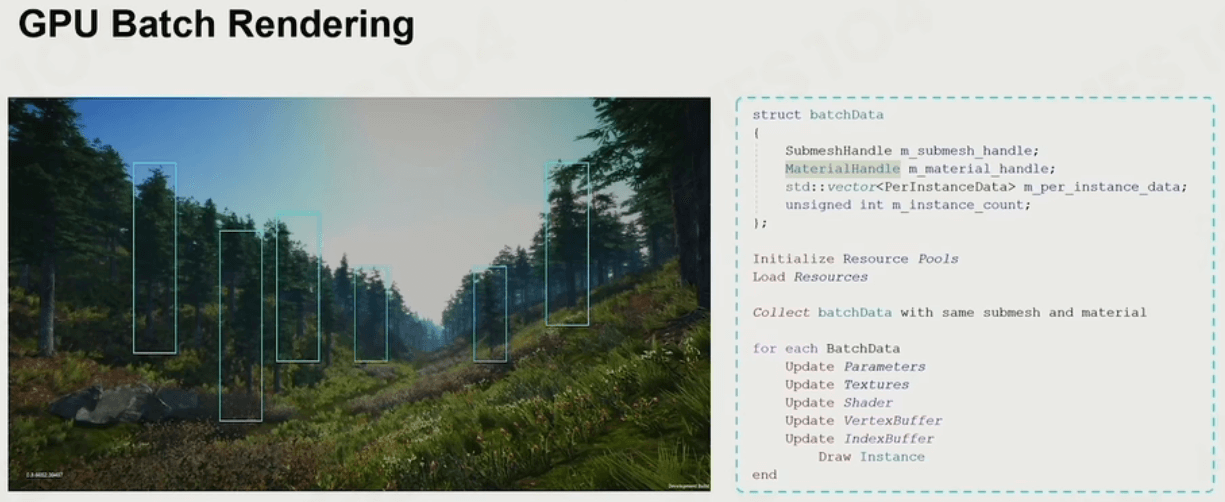
可见性裁剪
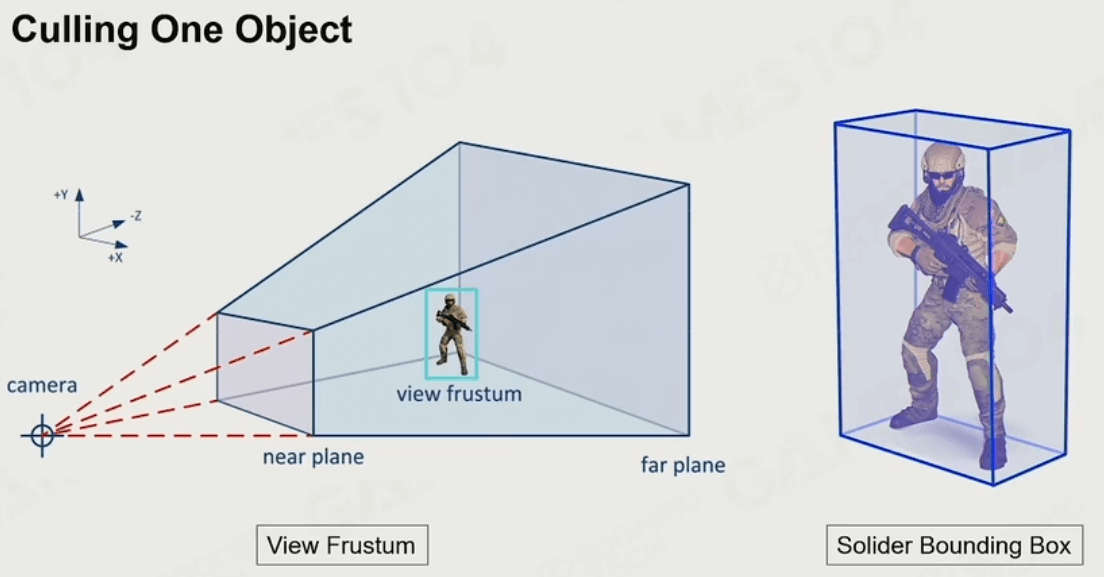
玩家的视野是一个视锥体(如下图),为了效率和性能,视锥体外的GO不考虑渲染。要使用到一个叫做 可见性裁剪(Visibility Culling) 的基础技术。GO被包围盒(Bounding Box)包裹,可以利用此技术来检测GO是否在玩家视野中。
包围盒
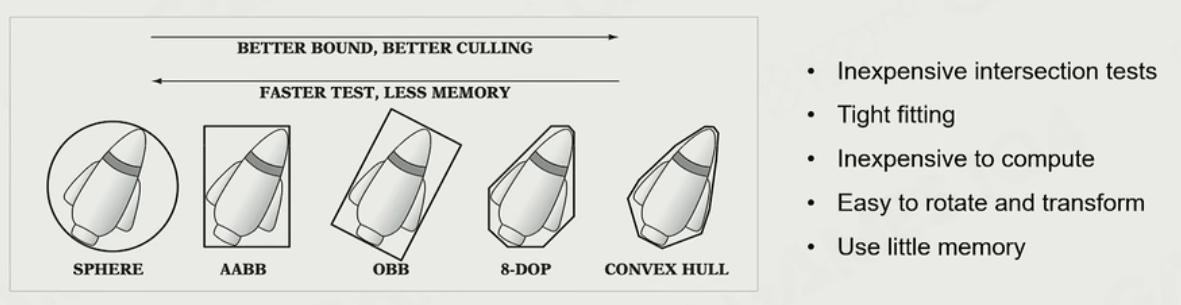
包围盒是很多计算的基础,因为如果直接对模型很多的面做计算,效率会很低。并且如上图所示,我们需要在包围盒的种类和裁剪的效果间做取舍/折中,达到最好的效果。
空间结构划分
在前面提到的空间结构划分技术,在这里也派上了用场:
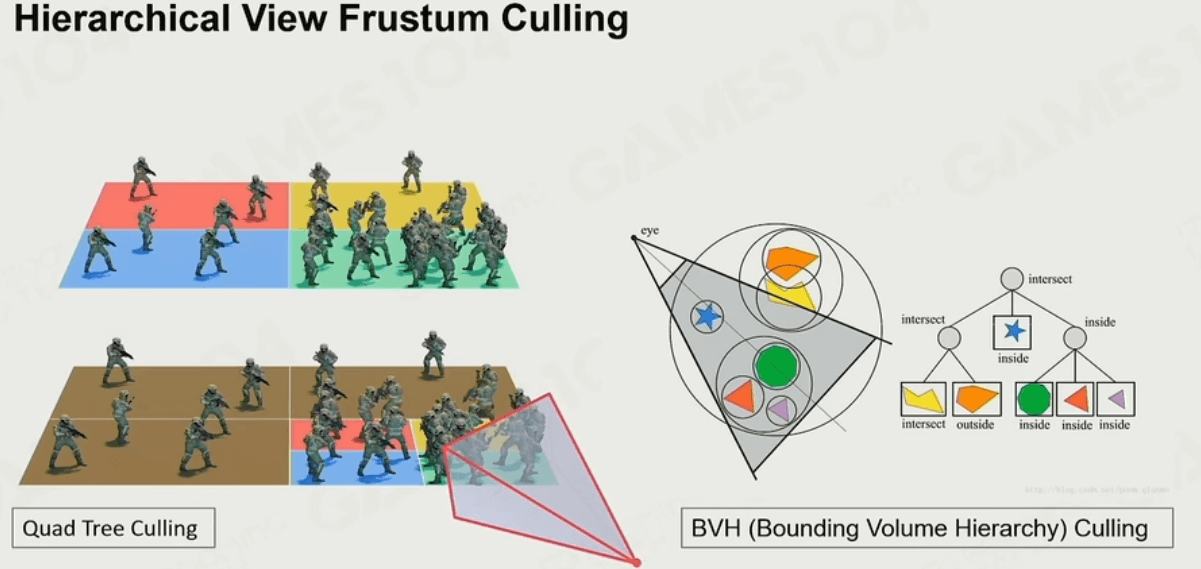
其中,BVH算法运用最广泛,虽然它不是最高效的算法,但它对动态物的空间划分有优势,可以节省计算时间。
PVS思想
PVS,即Potential Visibility Set,由卡马克大神提出。就是用BSP树将空间划分为若干区域,用Portal连接,渲染系统只需绘制玩家在此区域通过Portal看到的其他区域即可。
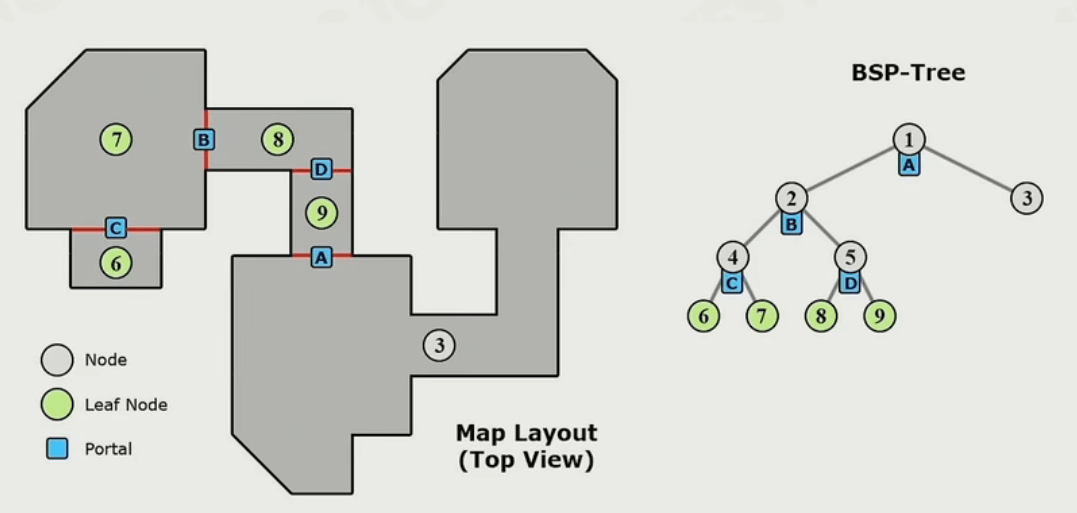

虽然这种方法在现代的可见性裁剪中不常见,但这种思想已经渗透入大世界区域的资源加载中了,运用好的话即可实现“无缝加载”:

GPU划分
现在使用GPU就能完成这项任务了,我们把一堆物体丢给显卡,他就会返回一串01序列,告诉谁可以被看见:
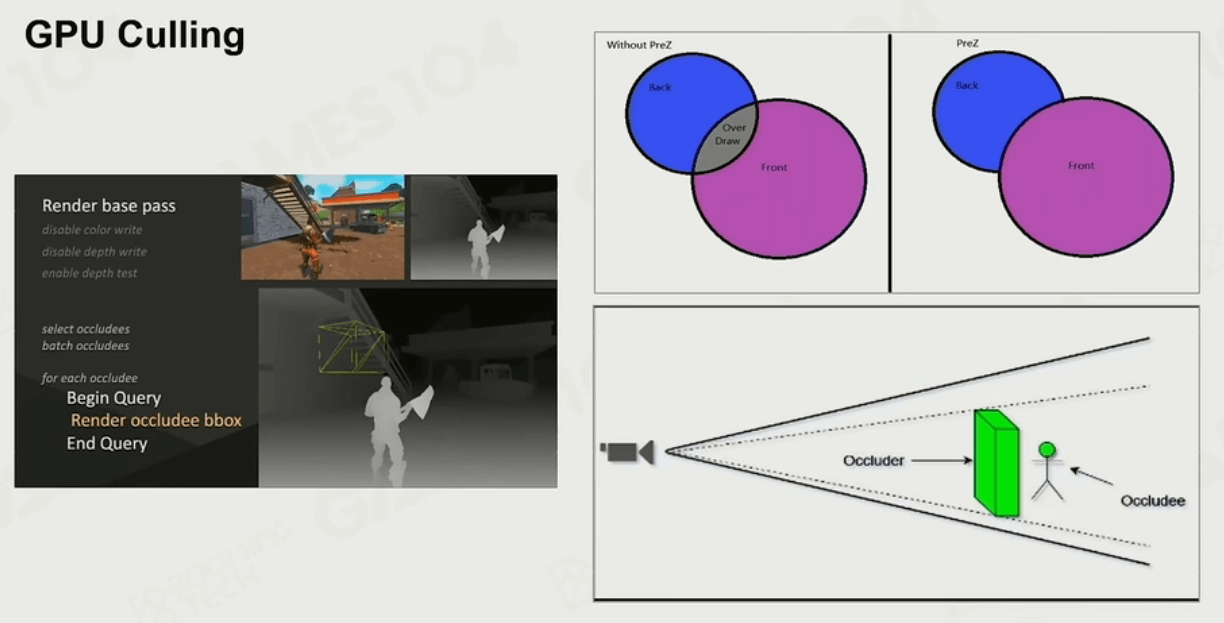
除此之外,GPU还有一种叫做Early-Z的技巧,它可以根据各种物体的深度信息来剔除不必要渲染的物体。这个小技巧对存在多物体的小房间等很有效。
因此,能在硬件上完成的事情就一定在硬件上完成。
纹理压缩

在游戏引擎中,纹理不是以纯图片形式(如bmp)存在,而是会进行一些压缩。但常见的JPEG和PNG压缩算法过于复杂,不符合游戏引擎的使用要求,因此,得自行采用其他的压缩算法。
块压缩

是纹理压缩的基本逻辑,详见工作技巧 | 纹理压缩格式Block Compression。
建模工具/方法

可以使用Blender(多边形建模类),Zbrush(雕刻建模类),实体扫描建模,程序化建模等工具/方法进行建模。
基于Cluster的模型管线
现代游戏的细节越来越多,精度越来越大,导致一帧内处理的数据量越来越大。因此一些新的渲染技术便出现了,如 基于Cluster的模型管线:
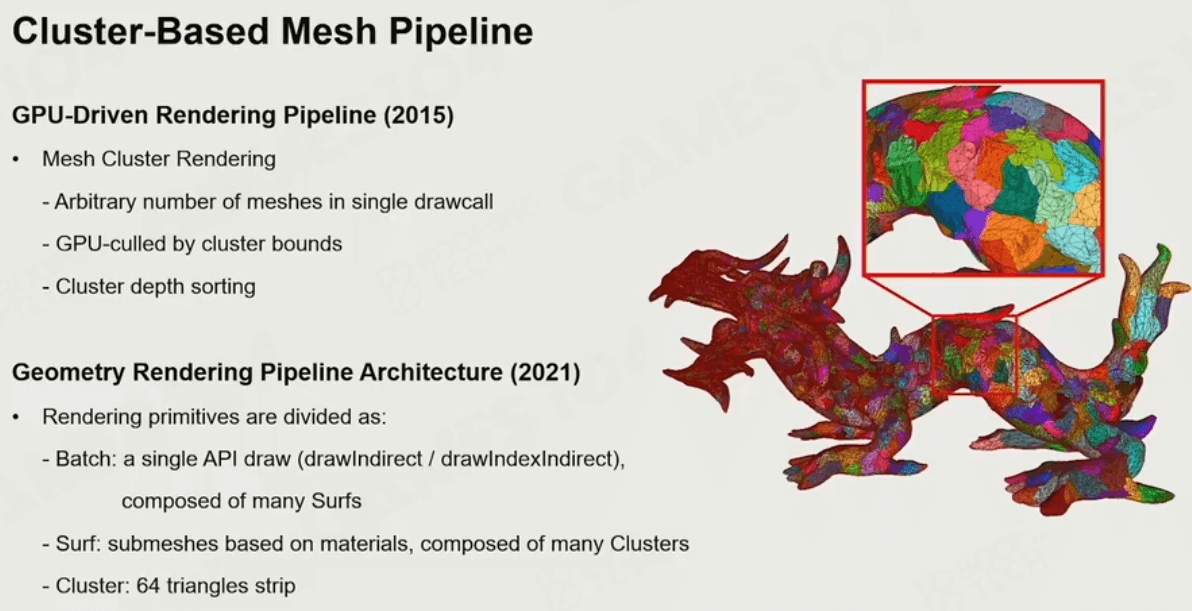
可以将模型分成许多小cluster,方便计算。
可编程
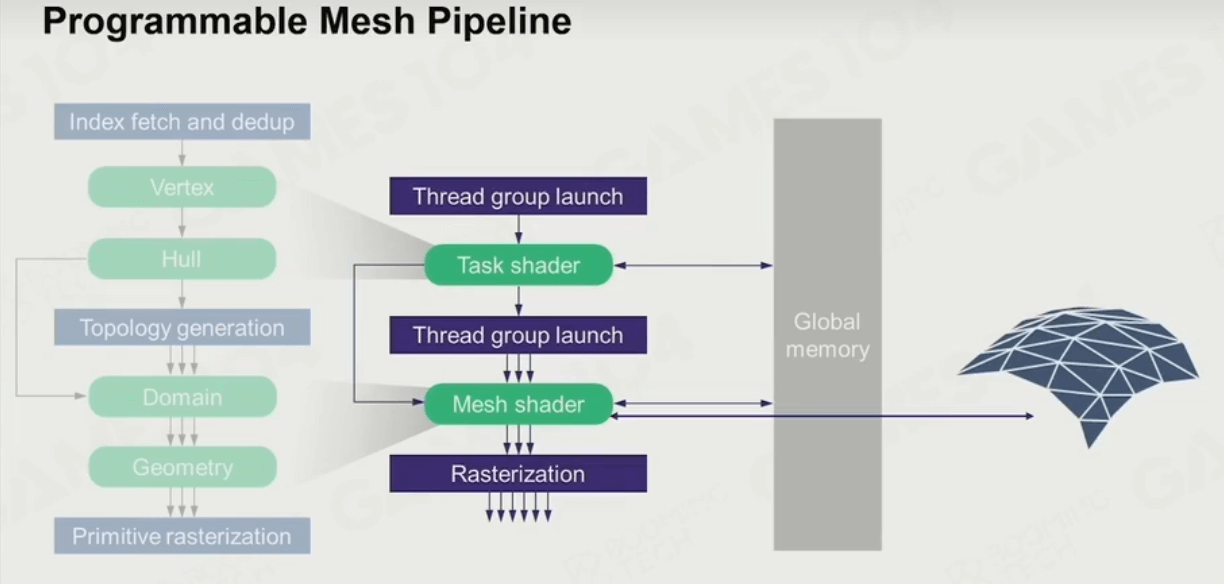
它是可编程的,通过对两个shader的编程,程序员和艺术家可以为所欲为,增添无数细节。
高效裁剪
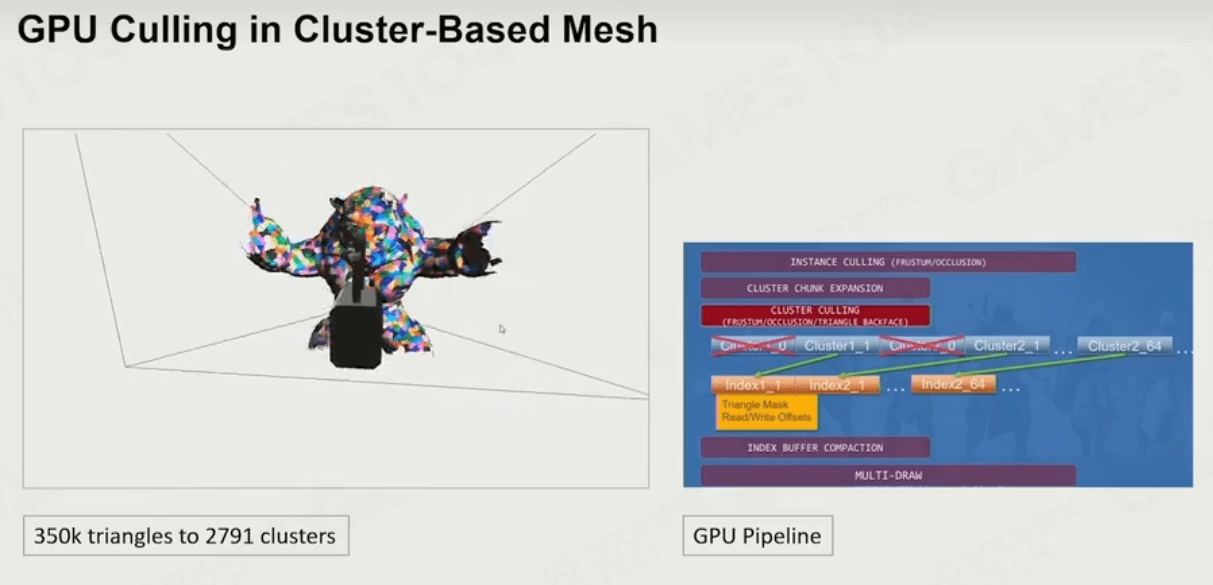
使用该渲染管线,可以用于基于GPU的可见性裁剪上,GPU可以快速计算出哪个cluster应该被渲染。
例子:UE的Nanite

UE的Nanite相当于此技术又往前一大步,有着像素级的网格,很强大。
参考资料
- GAMES104 (boomingtech.com)
- NVIDIA GPU 架构梳理 - 知乎 (zhihu.com)